Maybe you’ve heard that story about the pottery teacher who divided the class into two groups: half would be graded traditionally based on the quality of their work, but the other half would be graded on sheer quantity alone. As in, literally, he would take all the pots they made that year, weigh them, and X kilograms of pottery would get you an A+. As the story goes, the quantity group produced not only the most pots, but also unambiguously the best pots.
I’ve always been captivated by music, but much like many kids decide they “can’t draw” or “suck at math,” I likewise labeled music as a mystical alien magic that would forever be beyond me.
Later, in high school, I met a girl in the year below me who played the saxophone. She was really good and I assumed she started playing in elementary school. Nope, she started playing the previous year. That moment was the first click for me – you can just start learning new things, anytime. Even today.
The key argument is that it’s all about putting in the pracitce, the repetitions or “reps”, and not making excuses. From his own story:
It wasn’t easy learning an entirely new career, but I’m quite good at it now, and it didn’t take nearly as long as I thought it would. It turns out you can just learn new things if you have the right people to guide you and you have the opportunity and the inclination to put in the reps.
…
Learning, ultimately, is about putting in the reps. Figure out what you want to get better at, and practice doing it.
There’s a lot of things I would like to do. I mostly don’t do them. My reasons are all stupid excuses.
He outlines – and then rebuts – all the usual reasons we don’t learn more then outlines his solution, “operation garbage fountain”.
Basically a set of commitments to himself to just do the creative practice to get better, and to share it online in its raw form. Not concerned about quality, not concerned about the overall narrative arc of your posts, not concerned about audience or community building. And no guilt about posting too little or too much – just a commitment to make a little progress as often as you can, and to always post it in some form.
I love this. It’s a different take to what I also liked in Blogging as an Ideas Garden … but I’m not sure it’s incompatible.
This post from Jack Lindamood has a format I loved. The decisions and his reflections are interesting, but I think less interesting than the format itself. What I love:
You keep track of all the big decisions you’ve made during your tenure in a particular company / role
You engage in self reflection on if they were good or bad choices, after you’ve had time and benefit from hindsight
You share knowledge with the community (I was exposed to tech I’ve never heard of, and had new takes on tech I use every week)
If we had one of these for Culture Amp, it would go a long way to clarifying not just why we use a certain tech, but if we still like it, separate from the decision of if we’re still using it.
At Culture Amp we do use a tech radar that mimic’s the format from Thoughtworks. But the “radar” UI doesn’t lend itself to reading as a whole.
I also like that he’s captured the decisions he’s been accountable for as an engineering leader. That’s fascinating when thinking about recruiting – how do you convince a new company that you’re going to be a leader with good judgement? And how does the new company evaluate if the way you make decisions – and learn from mistakes – is the right fit for them?
It occurred to me recently that I feel extremely differently about ‘outputs’ via Twitter than blogs. I first came across the notion of the ‘ideas garden’ via Doug Belshaw and it suggests a blog can be seen as a place where you help ideas take root and grow.
This contrasts with the inherently performative feel of Twitter where the focus on immediate feedback means that individual item becoming a focal point for your reflection. In other words I care about the reaction a tweet gets because it is self-standing and immediately public whereas a blog post is an element of a large whole. It is a contribution to growing my ideas garden, for my own later use and whatever enjoyment others find in it, rather than something I have expectations of receiving a reaction for.
The blog itself then comes to feel like something more than the sum of its parts: a cumulative production over 13 years and 5000+ posts which captures my intellectual development in a way more granular and authentic than anything I could manage by myself. Over time I see old posts I’d forgotten about resurfacing as people stumble across them and this long tail heightens my sense of the emergent whole. It’s become an ideas forest which people wander into from different directions, finding trails which I had long since forgotten about and inviting me to explore a now overgrown area to see if I should begin tending to it once more.
I really like the “tech debt” metaphor. A lot of people don’t, but I think that’s because they either don’t extend the metaphor far enough, or because they don’t properly understand financial debt.
I learned things about debt and finance reading this, and it certainly helps bring much needed nuance to discussions about technical debt.
The discussion on Hacker News also had this comment that I loved, and I think I’ll use as alternative framing at work when discussing the need to keep code-bases healthy:
I worked with Ward Cunningham for about a year, and he said once that he regretted coining the phrase “technical debt.” He said it allowed people to think of the debt in a bottomless way: once you’ve accumulated some, why not a little more? After all, the first little bit didn’t hurt us, did it?
The end result of this thinking is the feature factory, where a company only ever builds new features, usually to attract new customers. Necessary refactors are called “tech debt” and left to pile up. Yes, this is just another view of bad management, but still, Ward thought that the metaphor afforded it too easily.
He said he wished instead that he’d coined “opportunity,” as in, producing or consuming it. Good practices produce opportunity. Opportunity can then be consumed in order to meet certain short-term goals.
So it flips the baseline. Rather than having a baseline of quality then dipping below it into tech debt, you’d produce opportunity to put you above the baseline. Once you have this opportunity, you consume it to get back to baseline but not below.
Back in 2018 I gave a talk at a few different meetups and conferences called “Your Web Page Never Listens To Me“, it was all about the Web Speech API and what voice / conversational user interfaces could look like for the web.
At the time, speech recognition was finally getting pretty fast and accurate, but all my demos were limited to saying things the computer was expecting to hear – much like a CLI, you had to give exactly the right command for things to happen the way you want, and the discoverability for what commands might exist was non-existent.
In 2023, we’re getting used to Large Language Models like Chat GPT, which are remarkably good at holding a conversation, and it feels like they do a decent job at understanding what you’re trying to say. It certainly makes my string matching and regex based conversation handling from 2018 look like something from the stone age. Perhaps ChatGPT or similar could help me get a conversational UI going to interact with web pages?
Most people who’ve just had a quick play with ChatGPT are impressed by how much it seems to know and how well it writes, but you quickly realise it can’t do anything. It can’t look things up. It can’t open some other app and do tasks for you. All it can do is chat. And when it doesn’t know something it makes it up.
My main source of following updates to the world of generative AI and large language models is Simon Willison’s blog, and in March one of his blog posts titled “Beat ChatGPT in a Browser” stood out to me: you can get these large language models to interact with “commands” or “functions”. You tell them about a function that you will make available to it, what the function do,es and how to use it, and it will try send a chat message with syntax for calling the function or command as part of the conversation. As a programmer you can then wire that up to a real function or command, that interacts with the outside world, and get it to do something useful. Very cool idea!
At the time I think I experimented for an hour or so trying to prompt ChatGPT to respond in ways that I could use programmatically with little luck, and figured it was a bit harder than it sounded, especially for someone who hasn’t spent much time learning how to work with large language models.
Well, last week Open AI announced an update that introduced “Function Calling” in their Chat APIs. This is using the GPT3.5 or GPT4 models with an API for declaring the functions you want to make available to the chat bot, and it can then utilise them as part of the conversation. Again I experimented for an hour or so, and this time, it seemed to mostly work!
So far my experiment looks like this:
A screen recording of my using a command line app. In the screen recording I type a prompt. You can then see a browser open, perform a web search, and open a web page. In the background the terminal is spinning information. Once it finishes the terminal prints the answer. The dialogue is below.
The dialogue of this interaction, in terms of messages between the user and the assistant, looks like this:
User: When and where is DDD Perth happening this year?
Assistant: DDD Perth is happening on 7th October 2023. The venue for the conference is Optus Stadium in Perth.
But there’s a lot more hidden dialogue making function calls, with 8 messages in total, 6 of them “behind the scenes”:
User: When and where is DDD Perth happening this year?
Function getTextFromPage() result:"Skip to contentMenuDDD PerthFacebook iconFacebook, opens in new windowInstagram iconInstagram...."
Assistant: DDD Perth is happening on 7th October 2023. The venue for the conference is Optus Stadium in Perth.
Now, there’s a whole bunch of problems here:
The language model I’m using only allows 4097 tokens, and the only option it has to read a page is to read all the text, which on most pages I try is at least 10,000 tokens. I had to cherry-pick the example above.
This is completely vulnerable to prompt injection. If I get it to visit a website the website could give new instructions to run functions I don’t want it to run, including opening web pages I don’t want it to open (porn, bitcoin miners, something that tries to take a photo of me using a webcam and post it to reddit…)
Interacting with it via a terminal isn’t really great.
I’m relying on a public search engine to locate the page I’m looking for, so it’ll often land on teh wrong page.
The function to get all the text often accidentally leaks JavaScript and CSS code into the output.
And probably many more things!
…but its exciting to see it work. I define a set of functions I want the LLM to be able to interact with, and I give it a natural language prompt, and it successfully navigates its way through my functions to answer the prompt using data from the real live internet.
I’ve just set up the ActivityPub plugin for WordPress, which should allow my posts here to be followed on Mastodon and other fediverse accounts using @[email protected].
I’m creating this as a simple post to see if it works, and how things like comment interactions work!
3 weeks ago I heard the incredibly sad news that my friend Li had passed away. I was his manager for a few years at Culture Amp, and to remember him, I want to share a few stories of conversations we had during out time working together that I think speak to the quality of his character.
Talented, but humble
Li was a remarkable front end engineer. He was quietly productive, building high quality user interfaces faster that almost anyone else around. It wasn’t uncommon to hear feedback that he’d finished building out an entire interface on his own while a whole team of back end engineers were still working on making the data available for it. Eventually people started to notice, and Kevin Yank, our Director of Front End Engineering, asked: how do you do it? Is there some secret the rest of us could learn too?
His answer still makes me laugh. “I’ve got my code editor set up really well.”
To this day I don’t know if he was just trying to deflect the compliment, or if he really thought that was his secret advantage. Tool sharpening is definitely a thing in our industry – we like to quote the proverb “Give me six hours to chop down a tree and I will spend the first four sharpening the axe.”
Li’s editor setup was simple, it wasn’t something he wasted time tweaking over and over, but it was effective. When I watched him work he spent his time thinking about the problem at hand, not trying to remember where a file was saved or trying to remember what a keyboard shortcut was.
Remembering it, I love the humility of his response – he didn’t boast, he wasn’t proud. He knew he was good at what he did, and was happy to share the things he found helpful.
Learning, to share
I remember a point where Culture Amp had just acquired a smaller company, and we were looking for some senior engineers to transfer in and join the team we’d just acquired to help them integrate their product into ours.
At first Li was interested in exploring the opportunity, but then backed out when he realized the move would be permanent, not a secondment from his current team.
We had some conversations to explore the opportunity, and he surprised me with his biggest motivation not being the desire for a lead role, or a high visibility project, or the desire to work with a team based in the US, but instead the chance for mutual learning. He wanted to work with an established team, see what he could learn from them, see what he could teach them, and bring that back to his existing team and work, sharing what he had learned. Which explained why he was interested if it was a secondment, but not permanent.
Throughout our time working together I was always impressed at his willingness to learn, be curious, do deep dives into a problem, and then to bring what he’d learned and share it back to the team around him so we would all benefit.
Contentment
I remember wanting to understand some of Li’s long term career aspirations, and I asked a question I learned from Kim Scott’s book Radical Candor: “At the peak of your career, what sort of work do you want to be doing?”
Most people have a few different answers to this, sometimes its a job title (“director of X”) or a specific role (“I want to be focused in Application Security”) or an ambition outside the industry entirely (“I want to run a small business, maybe a food truck”) or a personal goal (“financial independence, then volunteering”).
It was hard to get a picture from Li of a specific goal he was working towards, and the reason I eventually learned, is that he was content. He really liked the kind of work he did, and found it meaningful. He really liked the people he worked with. “I’m actually really happy in my current role” was something he’d say if I kept asking.
Contentment is rare. Especially in the high-growth software industry. When I think about Li’s good-hearted approach to work and life and his ability to actually enjoy the place he’s at, without longing for more, I think of this quote from the bible:
godliness with contentment is great gain.
Li found contentment, and I admire him for it.
There was a whole lot more about Li I never got to know that well – perhaps because of the manager/employee relationship dynamics, perhaps because we worked from different cities, we didn’t share much of our personal worlds with each other. There was a little bit – I’d hear about an upcoming dance congress he was excited about. Or how a lunch we shared reminded him of Sunday lunches after church with his family when he was growing up. Or about the ups and downs of buying, owning, renting out, and selling an apartment. I had no idea he could speak Spanish. I wish I’d had more time with him, and asked more questions, and shared more of myself too. But even without that, I’m grateful for having crossed paths, worked with, learned and laughed together.
Edit: it turns out for that the app Freedom that I talk about in this post, the problem is largely to do with Apple’s App Store policies. Their CEO Fred has left a comment below. My apologies! I did end up getting a coupon for my use, and the mistake in their support team refunded me for the price I paid on top of the coupon code. I use the app regularly and find it valuable. It’s worth checking out! But the UI pattern still annoys me so I’ll leave the blog post up. But without this clarification I’m probably being unfair to a pretty good product team.
One user experience pattern I find annoying is coupon codes. Or more specifically: offering me different prices so often that I’m anxious when purchasing that I might not be getting the best price.
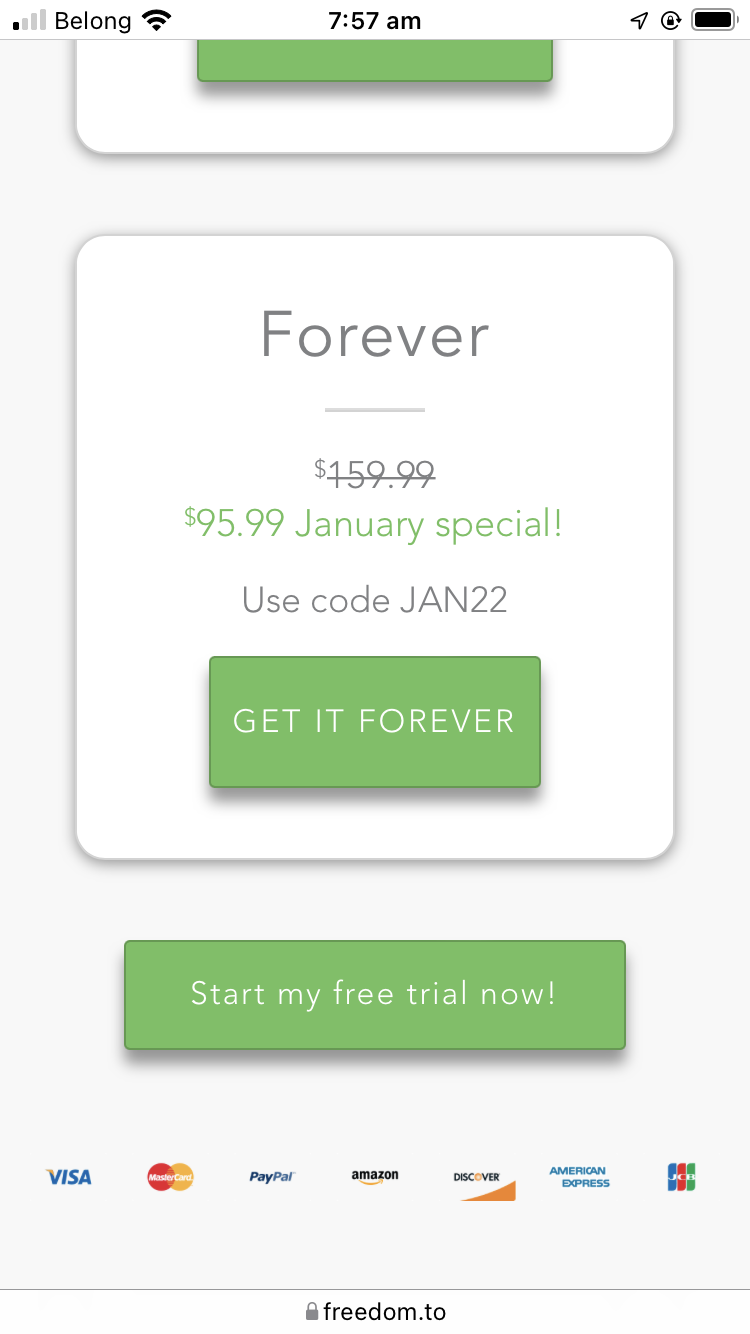
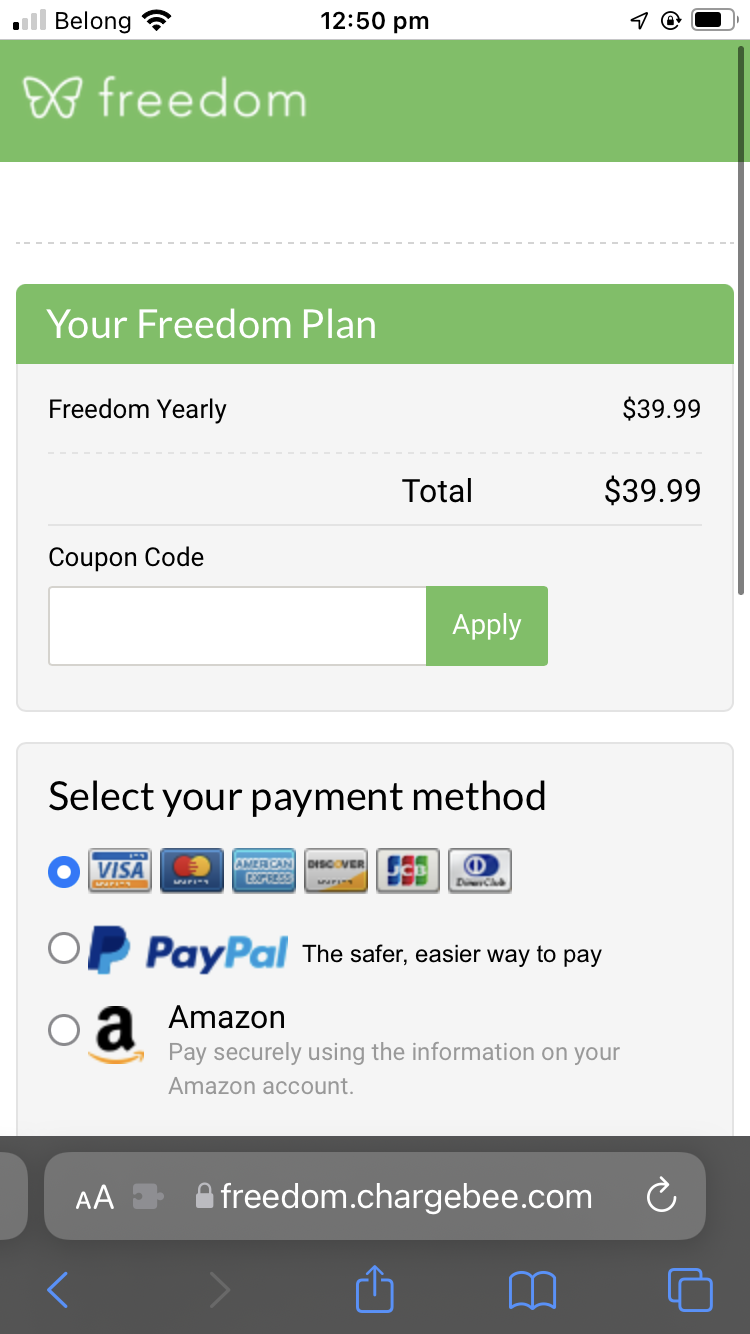
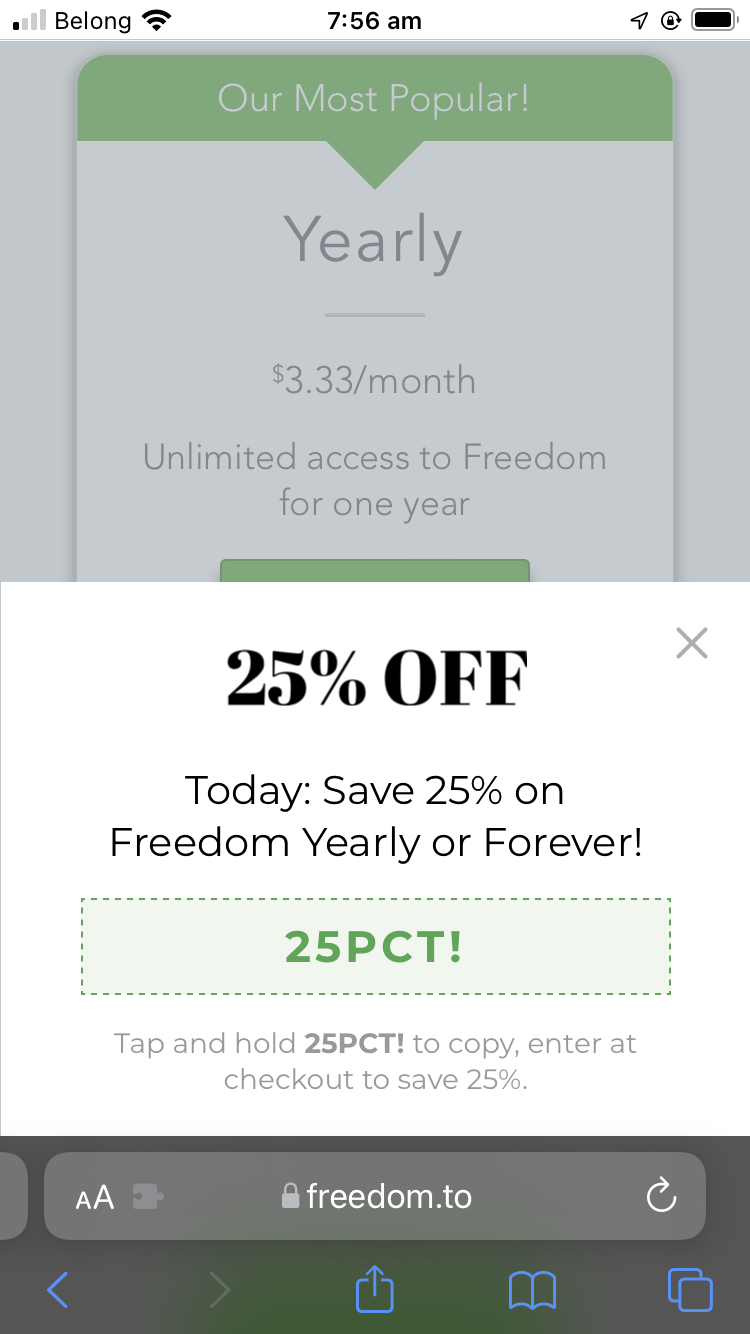
The price of the yearly plan I’m pretty sure I want. $20 less than in-app!
Viewing the pricing page 5 minutes later, a different discount!
The final price I paid, 50% less than the in-app price
A variety of the different price points I was offered while trying to sign up for 12 months, all on the same day.
The first price I saw was $60 in the iOS app. The same subscription on the website was 33% cheaper at $40. And there were two separate discount codes. In the end I saw a price for $29.99, which I tried to pay for.
Consistently offering different prices for the same product causes me to lose trust in the company, feel like I’m being cheated, and hesitate to pay, because I’m unsure of if there will be a better price tomorrow.
Frustratingly, I realized after the fact they’ve charged me $39.99. I’ve contacted their support to ask for a refund for the amount the coupon code would have saved me.
Overall, I’m enjoying the product itself – it lets you start a session that blocks distracting websites across all your devices, and does so at a VPN level so that tricks like switching browsers do not work – which is enough to break some of my time wasting habits.
But this saga with the pricing, which was either buggy enough or confusing enough that I ended up paying 33% more than I thought… has left a bad taste in my mouth. I think they must have analytics to prove the revenue benefit of this style of checkout in the short term, but I can’t help but think the brand/reputation damage isn’t going to help long term.
At Culture Amp we dropped support for Internet Explorer 11 in March this year, despite a significant portion of our annual recurring revenue coming from companies with over 10% of users still on IE11. We did that without complaints. How? Through a mix of customer conversations, clear planning, a neat technical trick, a focus on UX, and clear communication. Here’s the story of how we did it.
About us and our customers
To help understand the context we’re working in, it helps to know a bit about our company. Culture Amp is on a mission to create a better world of work, by building a software platform that helps companies understand their people and improve their company culture.
(p.s. Culture Amp is hiring engineers in Australia and NZ. It’s the best place I’ve ever worked. If you’re interested you can check out open roles or contact me, [email protected])
We have over 4000 customers ranging from small business to large enterprise. Some of our companies are progressive tech companies that have modern IT systems… and some still were using IE11.
Our leading product is an employee engagement platform which captures survey responses and shares insights and reports with millions of employees around the world. We care a lot about giving those employees a voice, and so we spend a lot of time making sure that our platform is accessible for as many people as possible. And browser support is a form of accessibility.
We don’t want to exclude people from our platform, and prevent their voice from being heard in their company surveys, because of their available technology.
Why we wanted to drop IE11
Having said that, supporting Internet Explorer 11 sucks. Most of our team are developing on MacBooks, so testing in IE11 requires either firing up a virtual machine or using a tool like BrowserStack. If you try to do this for every pull request, your pace of work really slows down. If you don’t, you start getting support tickets coming in because something unexpected broke in IE11, and those are hard work to debug too!
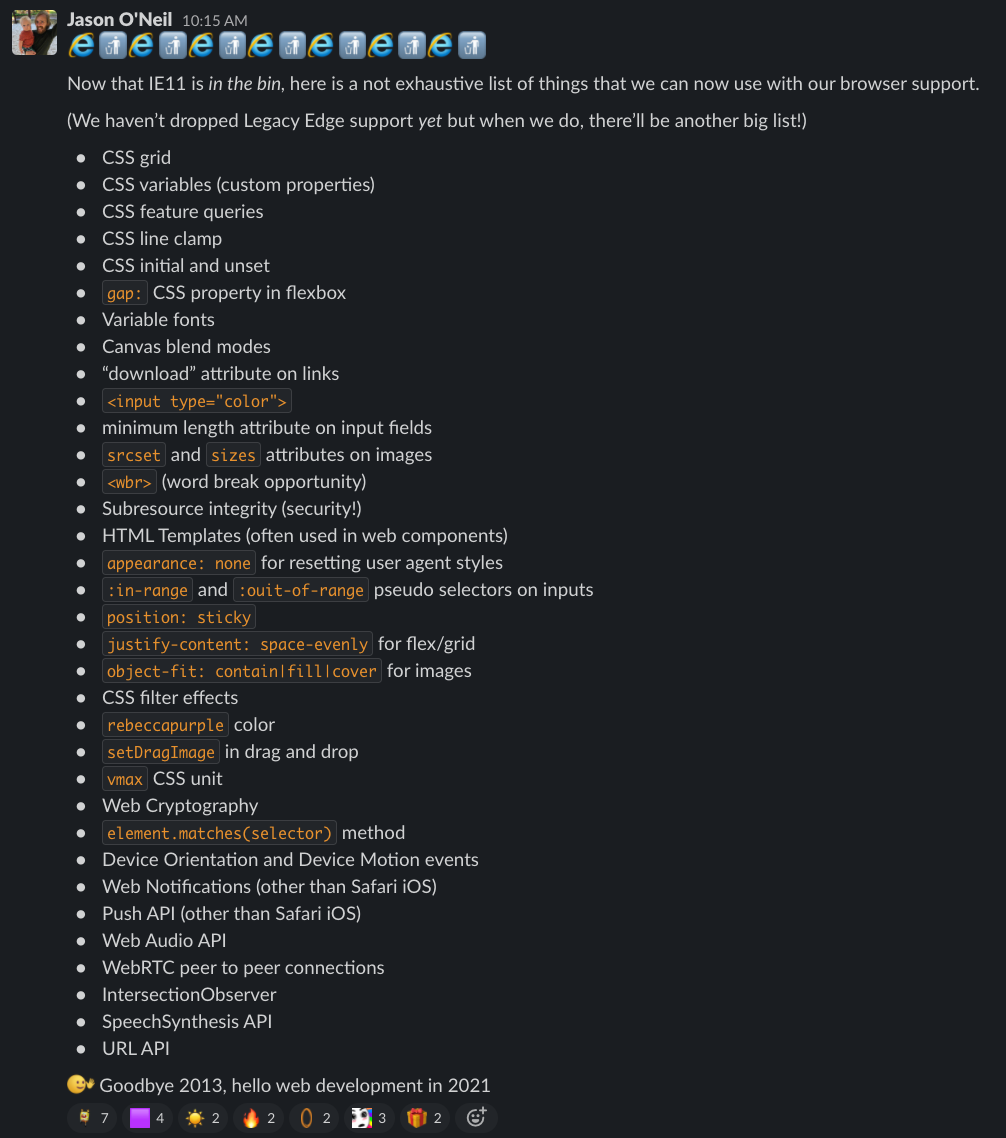
And also, we wanted to use new browser technologies. Being in the team that maintains our Kaizen design system, I was particularly excited about being able to use CSS Custom Properties and CSS Grid finally.
First question… is anyone still using it?
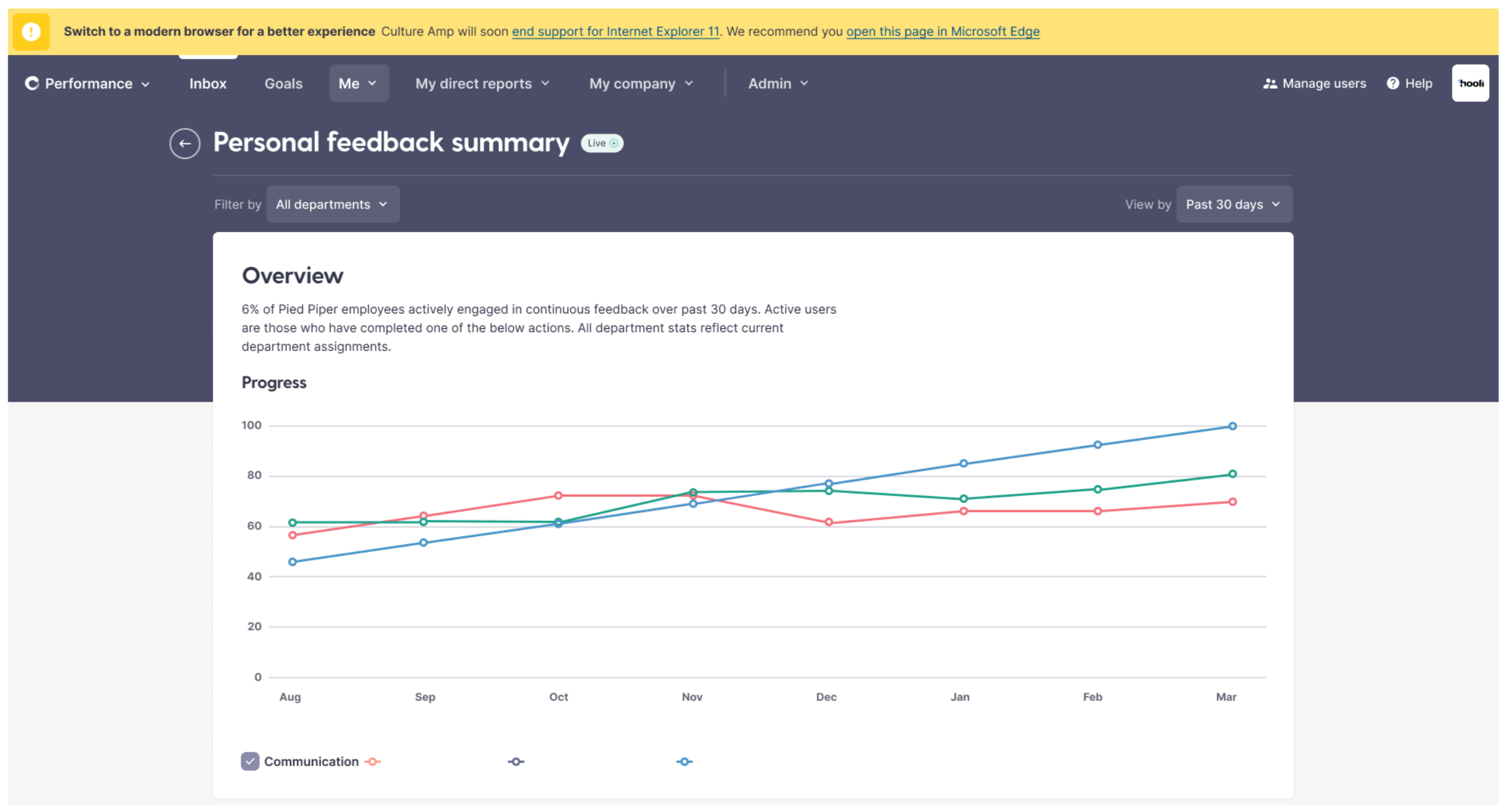
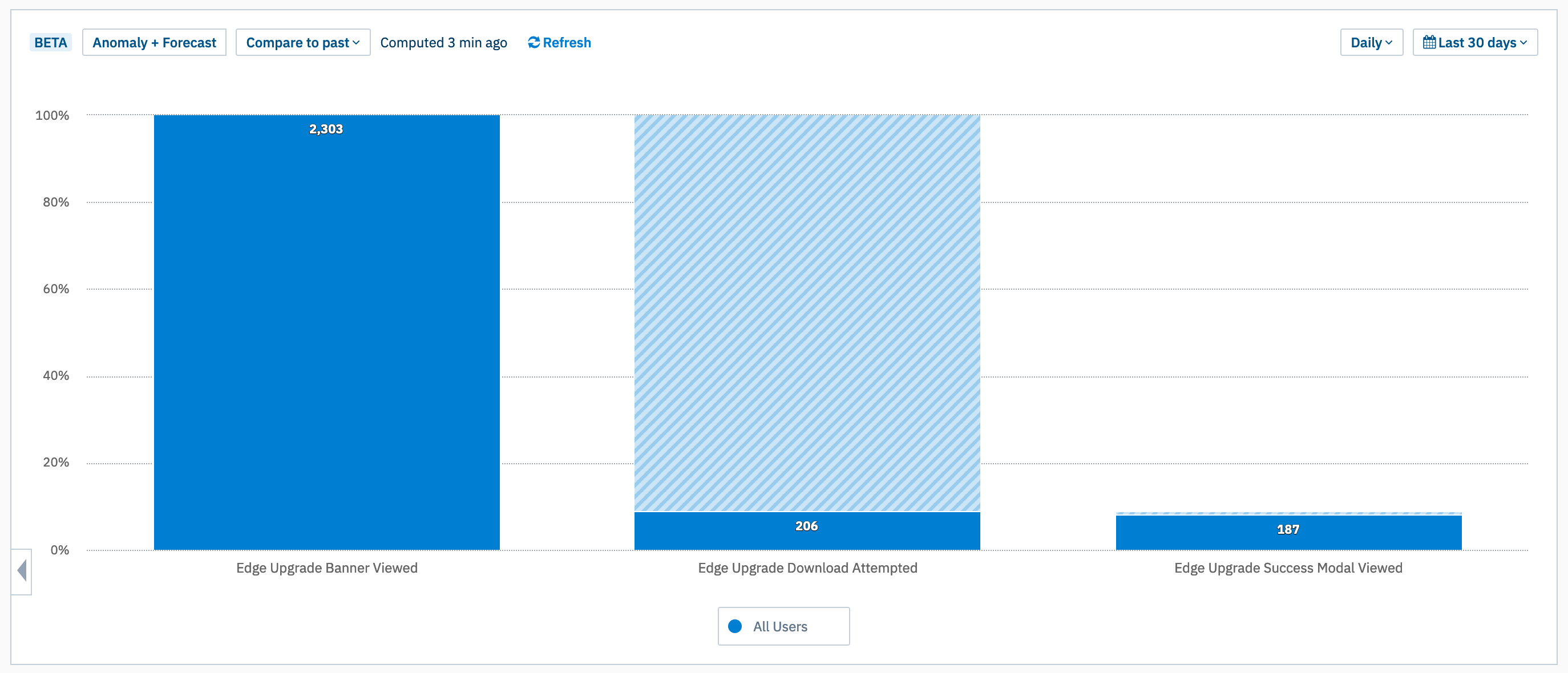
We were initially hoping we could look at IE11 usage and it would be so miniscule, no one would notice if we dropped support. (We dropped IE10 support when usage was below 1%).
Unfortunately, IE11 usage was sometimes still hovering around 8%, and some weeks went as high as 15%.
We wanted to understand it more, and so asked one of our analysts to look at the revenue amounts for the clients with high IE11 usage.
% of ARR
Accounts with >10% IE11 usage
18.6%
Accounts with >20% IE11 usage
9.5%
Accounts with >30% IE11 usage
4.6%
Accounts with >40% IE11 usage
3.4%
Accounts with >50% IE11 usage
1.5%
This table shows a huge portion of our revenue came from companies still with over 10% IE11 usage. We needed to make sure whatever our plan was, we didn’t upset this many customers.
This was pretty discouraging, but we continued to explore our options.
Starting with a conversation
My manager Kevin Yank reached out to one of our biggest customers, who we knew required IE11, and asked to chat to understand what the situation was on the ground, rather than just looking at the analytics and giving up hope. When we chatted to them, we realized this big customer did have Microsoft Edge installed on all of their computers, it just wasn’t always the default browser when people clicked a link from their emails. If we could convince them to switch to Edge, which they already had installed, maybe we could drop support for IE11 after all.
We ended up using a version of this to reach out to all customers of a certain size who had > 20% IE11 usage. Here’s the message we used:
We’re hoping to understand the use of Internet Explorer 11 at your company.
Now that the more modern Microsoft Edge browser is available on all versions of Windows we’re hoping to redirect users of the old Microsoft Internet Explorer 11 (released in 2013) to the modern Microsoft Edge browser.
This browser is getting more and more burdensome for us to support; the user experience of our product in that browser is getting worse and worse (it is both slow and increasingly ugly there), and we’re approaching a couple of technical decisions that, if we need to support IE11, will put us in a restrictive box for years to come. (Even Microsoft themselves are beginning to no longer support Internet Explorer 11 on some of their websites!)
We’d love to understand a bit more about your IT environment:
– Under what circumstances are your users needing to access Culture Amp through IE11?
– Is there a more modern alternative browser installed on those computers that you could switch to if necessary?
Are you able to get answers to these questions, or connect us with the right person so we can discuss?
We worked with our customer account managers to send this message to all customers above a certain threshold who had high IE11 usage.
The result: every one of the customers we spoke to said that employees would have another browser (usually they mentioned Edge, sometimes Chrome) also installed that they could use, but it might not be the default.
So… if they have a better browser installed, how do we get them to use it?
A technical discovery for directing users to Edge
With the Engagement product I mentioned earlier, a key to the success of the product is having high survey participation rates. We knew that if we started blocking ~10% of users (and in some companies, >50%) it was really going to hurt the product’s effectiveness.
We needed a way to have users switch browser with a high conversion rate.
So we began asking, is there a way to open a page in Edge from a page in Internet Explorer? We found our answer on Stack Overflow – there is, using a microsoft-edge: protocol in your links.
You could also use the custom-protocol-check package on NPM to check if the link click worked, and display a message on success or failure. (Unfortunately, it can’t tell you if it will work before the user attempts the action).
A screen recording showing the Codepen example and how a link in IE11 can open the same page in Edge.
There was a big scary alert warning before Edge would open, but if you allowed it, it did work. We hoped that with the write UX design and some encouraging copy, we could convince users to click a button, click allow, and open the link.
Stage 1 UX: a “soft” notification
The first phase was to show a persistent banner across the top of the page to all IE11 users, with a link that attempts to open the same page in Edge.
A screenshot of the notification design.
When we released this, we knew most people would ignore the banner, because ignoring banners is what people do. But for those who did click, it would allow us to get analytics on how many of them were able to successfully launch Edge.
We measured how many users saw the banner, how many clicked it, and how many had Edge open successfully.
The good news: even though only 9% of people clicked the banner, when they did, 90% clicked “Allow” and successfully opened the page in Edge. (Apparently the scary alert box wasn’t as scary as I thought!)
The banner displays in Internet Explorer 11. When the user clicks the “Switch to Microsoft Edge” link, a confirmation popup appears, and when they click “allow” the page opens in Microsoft Edge.
So, all we needed to do was force people to click the button. And that meant something more forceful than a notification banner.
Stage 2 UX: a “hard” interstitial page
We hoped a full page interstitial would do the trick.
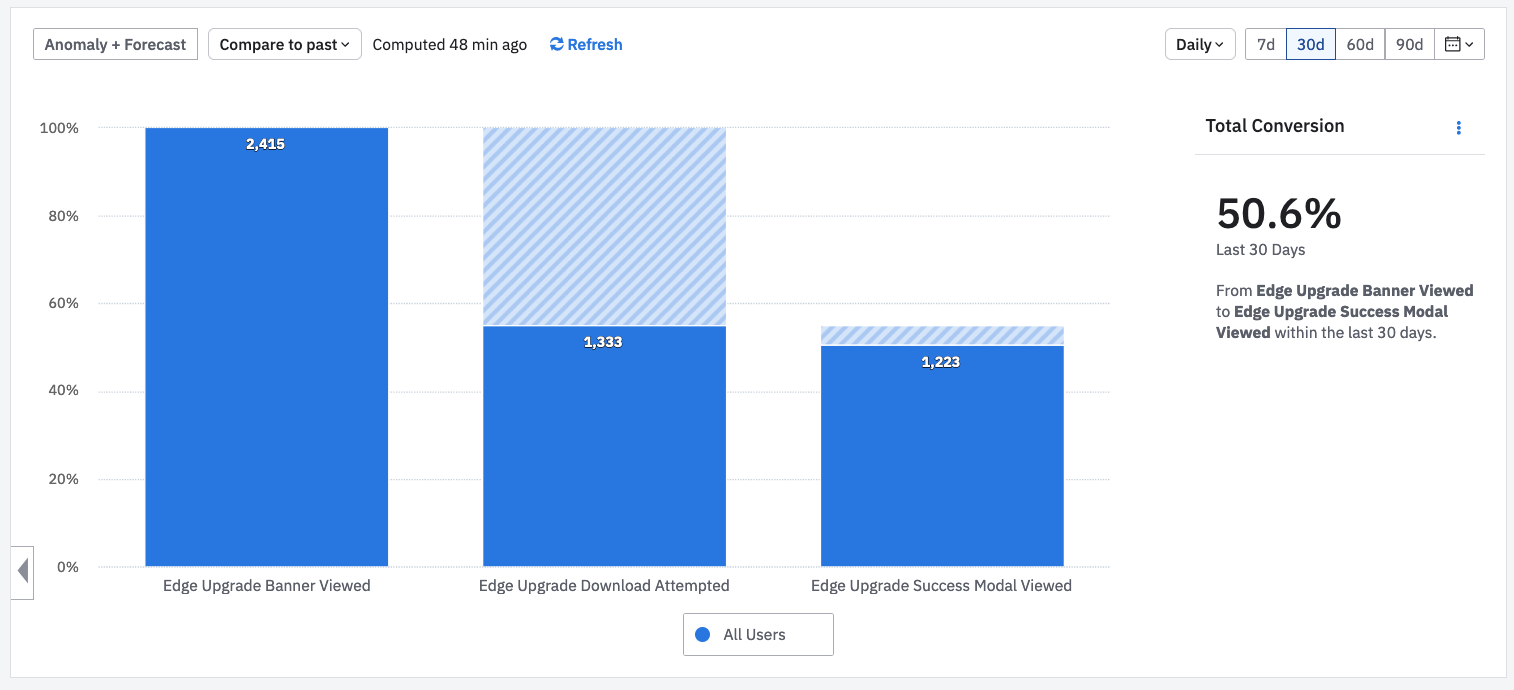
For the official end of support, we made it much harder to ignore. At our login screen, we redirected all users to a full page notification where the primary call to action is to open in Edge. This had much better results.
This looks healthier! The absolute numbers here are smaller a few months after the transition – people are now visiting from IE11 less often. But the percentages have stayed about the same since launch.
We now have 55% attempting to open in Edge, and 92% of them still succeeding, for an overall success rate of 50%. We believe most of the other users are switching to an alternative browser manually or bouncing.
Either way, this was enough to give us confidence that anyone who wants to use our platform, is able to. And our customers shared that confidence.
On login the user sees a full page notification directing them to open in Edge. They were 5x as likely to click “Open in Edge” here compared to the top-of-page banner.
The timeline
January 2021
Contact important customers to understand the impact.
January 27th, 2021
Initial email to all customers. Deprecation timeline added to support guide.
February 1st, 2021
Global Notification released and visible on all pages.
March 24th, 2021
Final email warning to all customers. Support guide updated.
March 25th, 2021
Support dropped. Interstitial Page released.
March 26th, 2021
We get to stop caring about IE11 and start using new browser features!
The result
Getting to announce this to the company was a special feeling.Getting to announce this to our front end engineers was even better
We released the change, and no customers were upset by it. We continued to see a healthy conversion of IE11 visitors to Edge by clicking the button, and a trend of less and less IE11 visitors over time.
Our teams no longer have to fix bugs in IE11, and no longer have to fire up a virtual machine to check their latest change in an ancient browser.
And we can now use things like CSS Custom Properties, which we’ve used to roll out a theme switcher in our design system.
What I’ve learned
Matching product analytics with business data (like account value) can paint an important picture of the impact a change will have.
Sometimes product analytics aren’t enough to tell the full story, and conversations with customers unearth a clearer picture, which can open up new options you might have assumed were unavailable.
Releasing a risky change like this in two stages helps! You can use analytics to validate a part of the conversion funnel you’re worried about (for us, if the “Open in Edge” button would actually work for people).
Large enterprise customers are more reasonable about old technology than I had originally thought.
Special thanks to my coworker Roy Zane who was my main collaborator in driving this project through to completion.
Writing a framework: web application architectures I’m inspired by
A look at recurring architectural patterns I see in both front end and back end, that have potential to tie together into a full stack framework.
In my last post I said part of my reason for wanting to write another web framework was that I’ve been exposed to similar ideas in both the front end and back end, and wanted to experiment with an architecture that ties it all together.
In this post, I’m going to explore those: Unidirectional data flow, the elm architecture, CQRS and event sourcing. And then I’ll look at the common themes I see tying them together.
State, views, and one-directional data flow
Almost every popular front end architecture I’ve encountered recently shares an idea: you have data representing the current state of your page, and you use that state to render the view that the user can see and interact with.
If you want to change something on the page, you don’t update the page directly, you update the state, and that causes the view to update.
You might have heard this described in a few ways:
Data Down, Actions Up: the data flows down from the state to the view. And the actions come up from the view to modify the state.
Model, View, Controller: Your have a data “model” layer that holds information about the current state, and a “view” layer that knows how to update it, and a “controller” that does the communication in the middle.
Unidirectional data flow: You often hear this term in the React ecosystem. Data flows from the top of your view down into it the nested components. So a component only knows about the data passed into it, and nothing else. The data always flows downwards. How do you change the data then? As well as passing down the data from the state, we also pass down a function that can be used to update the state.
Actions Up, Data Down. Every application has “State” (data for the application) and “View” (what the user sees). The view is always rendered and updated from the current state. (We call this “Data down”). And the view can trigger actions to update the state. (We call this “Actions up”).
This pattern is used in frameworks as diverse as React and Ember and Elm. Why is it so common? Here’s some of the advantages it provides:
Each function in your code has one job: turn the state into a view, or to update the state in response to an action. This makes it nice and easy to wrap your head around an individual piece of code.
The functions don’t need to know about each other. If you have a “to-do list” app, and an action that adds a new to-do item – you don’t need to know the 3 different places it’ll show up in the UI and change them all – you just update the state. Likewise, if you want to add a new view, you don’t have to touch all the places that edit the “to-do” list, you can just look at the current state, however it came to be, and use that data to render your page.
It becomes easy to debug. If there’s a bug, you can check if the state data is correct. If the state data looks correct, then the bug will be in one of your view functions. If that state data looks wrong, then the bug is probably in one of your action functions that change the state.
It makes it easier to write tests. Your action functions test simple things: if our state looks like this, and we perform this action, then the state should now look like that. That’s easy to write a unit test for. And for your view functions, you can write tests that use mocked state data to test all the different ways your view might be rendered. You can even create “stories” with Storybook, or take visual snapshots, for quick visual tests of many different ways the UI looks.
The Elm architecture
Elm takes this concept to the extreme. By making a language and a framework that are tightly integrated, they can force you to follow the good advice from “data down, action up”.
Messages – a message triggered by the UI (like clicking a button) that has information about an action the user is requesting (like attempting to mark an item as complete)
Update – a way to update your state based on “messages”
The Elm Architecture.
State. The page has some current state that is used to render the view. We use the type system to make sure the structure of this is consistent. In this example, it might have a title “My work” and a list of tasks like “Plan week” and “Check Slack”
View. Render HTML based on the current state. Following on the example above, we might have a view function that receives our state, and calls functions to render a <h1> element and a <ul> with the list of tasks, and a form for adding new to-do items.
Html. We never manually edit HTML or the DOM, we just update state, which updates the view, and the framework checks what HTML needs changing. In the example above, this would be the rendered h1, ul and form HTML / DOM produced by the framework.
Update. The only type of events we trigger from the HTML view are strictly typed and exactly what our update function is expecting. When an action happens, the framework uses the update function to consider what the new state should be based on the previous state and the action that occurred. Following on the example, an “AddTodo” action might append a new item to the list. While the “CompleteTask” action might remove an item from the list. The only way to update the state is to use the update function, one action at a time. This makes state management easy to unit test and debug!
There is also the opportunity to interact with the outside world – things like a Backend API. Elm provides a way to do this from the Update function (which can in turn trigger new actions) but it doesn’t have strong opinions on what happens in the Backend API.
And Elm will enforce this. You can only update the view of the page via your “view” function. Your “view” function only has access to the model to decide what to render. The only actions your view can trigger are the list of messages you define. And you can only update the state in the model using your update function to change things as messages come through.
And Elm has a fantastic type system and compiler to make this all work really nicely together. To show how it works, imagine you have a “to-do list” and you have a button to mark an item as complete:
In your “view” function where you render the button, you can set an “onClick” event.
The “onClick” event will trigger a message that something has happened. You decide the names of the possible messages that can happen, so we might chose a name like “MarkToDoAsComplete”.
Because we have told Elm we have a message called “MarkToDoAsComplete”, it will force us to handle this code in our “update” function.
In our “update” function we write the code that updates the model, setting the current to-do as complete.
When a user views the page they see the button. When they click the button, the message is triggered, the update function is run, the model is updated with the to-do item now being marked as complete, and the view will update in response. By the time we did all the things the compiler asks, it all just worked.
The great thing about this is that Elm knows exactly what code is needed for all the pieces of your application to work. If you’re missing anything, it will give you a nice error message showing what to fix. This means that you never get runtime errors in your Elm code.
But even nicer than that, it means you have a great workflow:
You add your button, and a “MarkToDoAsComplete” message
The compiler tells you that message needs to be added to your list of app messages. You do that.
The compiler tells you that your “update” function needs to handle the message. You do that.
It now all works.
This “chase the compiler” workflow is what originally got me excited about the Elm language, not just the architecture – you can see Kevin Yank’s talk “Developer Happiness on the Front End with Elm” for a more detailed overview.
(As a bonus, if you do spot anything wrong, the strict framework for updating state based on actions, one at a time, allows powerful debugging tools like “time travel debugging”, where you can replay events one at a time to see their effect.)
Command Query Responsibility Separation (CQRS)
On the back end, we sometimes find a similar pattern to “data down, actions up”. It’s called “Command Query Responsibility Separation”. You separate the queries (data) and the commands (actions) into separate code paths, separate API endpoints, or even separate services.
If your back end uses an SQL database, you can think of the “queries” using SELECT statements, and the commands using INSERT or UPDATE statements.
Command Query Responsibility Separation (CQRS) encourages splitting up the “queries” (ways of reading the state) from the “commands” (ways of modifying the state). This ends up with many of the same benefits as “data down, actions up”, but for back end endpoints or services.
We use separate code paths for Commands (writes) and Queries (reads). Rather than having an API return new data after a command, we have the client repeat the full query.
And you end up with similar advantages:
Each endpoint has one job.
The endpoints don’t need to know about each other.
It becomes easier to debug.
The command endpoints and the query endpoints can adopt different scaling strategies. For example caching can be applied to the “query” endpoints.
Event Sourcing
When we talked about the Elm architecture, we saw a front end framework with a strict way to update the current state: by processing one message at a time. Event sourcing brings a similar concept to our back end, and crucially, to our data and our “source of truth”.
It’s normal for the “source of truth” in a web application to be a database that represents the current state of all of your data. For a todo list, you might have a row for each todo item, and columns to set the text of the item, whether it is complete or not, and the order it appears in the list.
That table would be your source of truth.
Event Sourcing – changing the source of truth. Traditionally in a web application the “source of truth” might be a database table that represents the current state of the application. In event sourcing, the source of truth is an event log: all of the actions that occurred, one at a time. We can use this event log to build up a view or the current state.
Event sourcing is about changing the “source of truth” to be the events that occurred. Rather than caring exactly which todo items currently exist, and if they are complete, we care about when a user created a task, or marked a task as complete, or changed the order of the tasks in a list. These are the “events”, and they are our “source” of truth.
And we can process them, one event at a time, to build up a view of the data (in event sourcing these are often called “projections” of the data). Some projections might look very similar to what we had before – a database table with a row for each todo item, a column for the item text, whether it is complete, and the order in the list.
The power of event sourcing is that we can also create other views of the data. Perhaps we want to create a trend line graph showing how many open tasks we’ve had over time. If our source of truth was the current state, we wouldn’t be able to tell you how many tasks you had open last week (or this week last year!) With event sourcing, we can go back over all of the events, and build new views of the data.
Event Sourcing allows us to create different “projections” for different ways of viewing the data.
Client actions. We can start with actions that are triggered by the user. Event sourcing as a pattern has no strong opinions on how this is handled.
Command handler. A service takes the action coming in from the client (like ticking off a task) and decides if it is allowed. If it is, it adds it to the event log.
Event log. A log of all the events that have occurred. Often this is in a database table. In the diagram above, we show 4 events: “Create Task”, with id “1” and task “Draw Diagram”. Then “Create Task” with id “2” and task “Write post”. Then “Complete Task” with id “1”. (Meaning “Draw Diagram” is complete). Then “Create Task” with id “3” and task “Clean dishes”.
Here the diagram splits into two, because rather than just having the task list, we can process the events and generate other interesting data. These “projections” are different data to derived from the same events.
We have a “Your Tasks projection” that is a database table with “id”, “task” and “complete” columns. Based on the events, Task 1 “Draw diagram” is complete, while 2 “Write post” and 3 “Clean dishes” are not. This could be used to render a traditional to-do list UI.
And we have an “Open Tasks Graph projection” with two columns, “date” and “open tasks’. It shows how for any given date, we can see how many tasks were opened. We could use this t draw a trend line graph.
Similar to the front end with actions and state, this also opens up some powerful debugging options. We can replay the events and “time travel” to see exactly how our system responded, and look out for points where things may have gone astray.
Bringing it together: the common concepts Iwantmy “Small Universe” framework to draw on
You probably spotted some similar themes running through the above architectures:
Keeping code to fetch data and code to process actions separate
Having a way to get the “current state” for a page from our data
Always rendering the pages based on that current state
Allowing the views to trigger actions or “events”
These events being tracked, and considered our source of truth
Responding to one event at a time to update our application data
Following these allows us to write code which is simpler – each function is focused on either fetching data for the current view, displaying the current view, or processing an action. That makes code easier to understand, easier to test, and simpler to debug.
Making sure our data is updated one action at a time also opens up potential for time travel debugging, which is an incredibly powerful feature for you as a developer when you’re investigating how something went wrong. It also leaves the door open for new features that you can build, being able to take full advantage of all the past user actions.
Finally, by strictly defining the shape of your state, and the set of actions (or “events” or “messages”) that are possible, you can have the framework and compiler do a lot of work for you, ensuring that if a button exists, it has an action, and the action updates the state, and the view reflects the updated state.
So you can find a very productive workflow where you start adding one new line of code for your feature, and the compiler will guide you all the way to completing the feature as valid code, and you can be relatively confident it’ll work.
So, for this “Small Universe” framework I’m starting, I am taking inspiration from these architectures to try build something that leads you to write code that is easy to write, understand, test and debug. Something that uses events as a source of truth to make it easy to build new features that process previous actions into features or views we hadn’t imagined up front. And something that leads to a happy and productive workflow, with the compiler able to provide ample assistance as you build out new features.
I’ll come back to describe the architecture I’m aiming for in a future post. But I hope this helps you understand the direction from which I’m approaching this project.
Have any questions? Things that weren’t clear? Ideas you want to share? I’d love to hear from you in the comments!
This is my idea, I thought. No one knows it like I do. And it’s okay if it’s different, and weird, and maybe a little crazy. I decided to protect it, to care for it. I fed it good food. I worked with it, I played with it. But most of all, I gave it my attention.
“What do you do with an idea” by Kobi Yamaha and Mae Besom.
I’m thinking about writing a web framework. This wouldn’t be my first time.
Why?
Primarily, because I’ve got an idea, and want to explore it. The quote and photo above from “What Do You Do With An Idea” reminded me that creativity and inspiration are muscles we can train – the more we explore our ideas with curiosity, the more the ideas will keep coming.
I want to play with code more, try out things for the sake of curiosity and experimentation and be okay with it not necessarily building toward something as part of my day-job.
I’m a software engineer that enjoys building the thing to build the thing. At Culture Amp, I’m on the “Foundations” team that builds things like the design system and our common tooling, rather than working on the main products.
Every now and then I want to build a little side project, but get paralyzed – what should I build it with? None of the existing web frameworks I look at appeal to me – I want a single framework for front end and back-end, I want a language with a good compiler, and I want something I can grasp from front-to-back, if there is magic I want it to be magic I understand.
I’ve learned a lot since I last tried this. In particular, at Culture Amp I’ve been exposed to languages like Elm on the front end and concepts like Event Sourcing / CQRS on the back end. And they’re similar and interconnected and I want to see what it looks like to build a framework that builds on patterns from all of these.
I’ve enjoyed this kind of project in the past!
(Side note: I’m aware that being in a position where I have the time and money to indulge in this is a sign of incredible privilege… I’m still learning what it means to actively tear down the unfair systems that contribute to that privilege. There are more significant things I can invest my time in for certain. But I’ll save that for another blog post 😅)
What have I tried in the past?
I once was the main developer (including doing a ground-up rewrite) of a framework called Ufront. It loosely copied MVC.net on the backend, but could compile to several backend languages (thanks to Haxe). The killer feature was that you could re-use code – routing, controllers, views, models, validators – on the front end, and have seemless compiler help when calling backend APIs from the Front End.
To this day I haven’t seen another framework attempt that level of back-end front-end integration, with the possible exception of Meteor. (Admittedly, I haven’t been looking for a while). I feel this tried to be too many things – being a generally useful backend, as well as a front-end integration layer, as well as an ORM, and Auth system, and more. At the end of the day, with the majority of the development coming from me, it didn’t have momentum for such an ambitious scope. I did build two useful education apps with it though!
I also attempted a more tightly scopoed project that never got off the ground, called “Small Universe“. I started this around the time I was interviewing for Culture Amp, and it was heavily influenced by Kevin Yank’s talk “Developer Happiness on the Front End With Elm“. (I now work with Kevin at Culture Amp). The idea was to have a clear data flow for a small “Universal Web App”. The page can trigger actions. Actions get processed on the back end. The back end can generate props for a page. Then the props are used to render a view. Basically, the Elm architecture but with an integrated back end / API layer.
I liked this a lot, and built out quite a prototype, but haven’t touched it in over a year. I like this scope of “small, opinionated framework to give structure to a universal web app”.
The first prototype I built integrated with React on the client, which I think I’d skip this time. I also think I’d go further with the data flow and push for event-sourcing (I didn’t know the terminology at the time, but I’d implemented CQRS without Event Sourcing).
I also liked the name, and think I’ll reuse it! “Small Universe” spoke to it being a framework for “universal web apps”, where code is shared seamlessly between client and server. And also it being “small” – giving you all the building blocks for an entire app in a tight, coherent framework that is easy to build a mental model for.
So am I going to do this?
I think so! I’m interested in having a project, and “working out loud” with blog posts alongside PRs to explore the problems I’m trying to solve and the approaches I’m experimenting with.
I don’t think it’ll necessarily become anything – and there’s a good chance I’ll not follow through because life gets busy (my wife and I are expecting a second child next month 😅) but I’m interested in sharing my initial thoughts and seeing where it goes from there.
What am I optimizing for?
Scribbles from my iPad as I explored what I’m optimising for. (The section below is derived from this).
My own learning, curiosity and practice. (See “Why” above)
An Elm like workflow, but full stack. Elm has this great workflow where you can create a new button in your view. The compiler will ask you to define an action for the button. Once you define an action (like `onClick save`) the compiler will ask you to write an “update” handler for when that action occurs. When you do that you’ll write the code to handle the save. You start with the UI, and then the compiler guides you through every step needed to see the feature working. By the time the compiler has run out of things to say, your front end probably works. I want the compiler to provide that experience, with guidance, hints and safety to build features across the front and back end stacks.
Clear flow of data and logic. Every piece of logic in the app should have its place in the architecture, and it should be easy to find where something belongs. On the back end this looks like CQRS (Command Query Responsibility Separation) – having the code paths that fetch data for a page (Queries) be completely separate to the code paths that change data (Commands). On the front end this looks like separating out state management from the views – the page state should be parsed into a view function. There’s lots to dive into here, but I’ll save it for a future post.
Start small but keep options open. I want this for myself and side projects. I want something that can start small, and where the entire mental model can fit in my head. But which makes it easy to migrate to a more traditional framework, or a more advanced architecture, if the thing ever grows.
Keeping open the possibility for a host of technical nice-to-haves:
Event sourcing.
Offline client-side usage.
Multiple projections.
Server side rendering.
GDPR “right to be forgotten”.
Using Web Sockets for speedy interface updates.
Ability to have “branch previews” so you can see what a PR will look like.
And to call out some trade offs:
I’m not aiming for compatibility with React or other view layers. I think the idea I’m chasing handles data flow differently enough that it’s not worth trying to shoe-horn existing components.
I’m not aiming for micro services. For side projects I think a “marvelous monolith” is more sane. If the data is event sourced a future transition to micro services will be easier.
Not aiming to support multiple back end targets, or front ends. I’ll probably pick just one back end stack to focus on, and focus on the web (not native / mobile).
Not aiming for optimum performance. If I can write an API signature in a way that can be optimized and parallelized in future, I will, but I’ll probably do some naive implementations up front (such as updating all projections synchronously in the main thread).
Not aiming to be a general HTTP framework that can handle arbitrary request and response types. There are plenty of good tools for that job.
Hi 👋 I’m Jason. I’ve been a remote worker since 2016. Full time remote since 2017, and managing a team remotely since 2018. With people across the world suddenly finding both themselves and their teams homebound, I thought it might be a good opportunity to share some of the things I’ve found helpful as a remote team lead. I work at Culture Amp, a software platform that helps organisations take action to develop their people and their culture. We have a collection of “inspirations” – ideas you can copy in your organisation to improve its culture. I’ve followed the basic format here.
Facilitating good meetings requires having a bunch of tools in the toolkit to make sure everyone gets a chance to speak, people are understood, and it is a valuable use of people’s time. The tools you’ll use for video meetings are slightly different, so it’s worth getting familiar with them.
Why?
Video meetings present slightly different challenges: there can be poor connection quality, non-verbal communication is limited, it’s more likely people will attempt to multitask, and less likely you’ll know if they are, and there’s no obvious “clockwise” direction to go around the room when seeking everyone’s input.
Instructions:
Here are some tools to add to your toolkit:
Recreate “going around the room” to let everyone have a chance to share. You can do this by having the first person to share choose who goes next. As each person shares, they choose who goes after them. This is a good technique for “stand-ups” and other similar status update meetings.
Use hand gestures to signify you would like to speak next. Because of the slight delay on video calls, when multiple people want to speak up it’s hard to not speak over each other. Rather than wait for a gap in conversation and jump in, signify you would like to speak next by raising your hand with one finger up – you’re first in line to speak. If a second person also wants to speak, they can raise their hand with two fingers up. Usually a group learns this system quickly but it’s important the facilitator respects the order.
If people have noisy surroundings, ask them to mute unless speaking. If someone on the call is in an open plan office, is working from a cafe, has children nearby or even noisy animals outside, these can all make it harder to hear the person speaking. Encouraging people to mute by default makes it easier for everyone to hear.
Encourage everyone to have video turned on. It helps with non-verbal communication, and for someone speaking to see if they are being understood. Exaggerated head nodding, thumbs up, and silent clapping are all great ways to give feedback even while muted, but only work if the video is turned on. Exceptions can be made if the connection quality is poor, or if it is a presentation rather than a meeting.
Consider screen sharing a document that serves as both the agenda and the minutes, and editing it live. Adding a visual medium alongside the conversation helps participants keep focused and can give extra context. Taking notes and recording actions in the moment is a great way to ensure people are aligned and there aren’t misunderstandings.
Be conscious of how screen-sharing impacts non-verbal communication. Often when you start screen sharing, the other participant’s screen is now dominated by the screen share, and the faces of their colleagues are reduced to thumbnail size. This reduces the bandwidth of non-verbal communication like facial gestures and body language, and can make it easier to have your tone misinterpreted. For sensitive conversations, consider turning screen sharing off.
If you have a dual monitor setup, some products like Zoom have settings that allow the screen sharing to take up one full screen while still seeing participant faces in full size on the other screen. This is worth setting up if you can!
Use “speedy meetings” to allow time for breathing and bathroom breaks. When someone has back-to-back meetings in an office, they usually have breathing space as they move from one room to another or wait for the next group to arrive. When video calls are scheduled back-to-back the calendar can be a cruel task-master. Scheduling you meetings to run for 25 or 50 minutes (rather than 30 or 60) gives everyone a chance to breathe and can drastically reduce the stressfulness of a day. Important: if you schedule a speedy meeting, respect everyone by finishing on time.
Make space for “water cooler” talk on the agenda. Make sure the first five minutes or last five minutes of the meeting have space for the people to chat casually and catch up. In an office this often happens on the way to a meeting room, or on the way out, or around an actual water cooler. When it’s a video call, you have to be more deliberate. Make sure the agenda leaves enough space for this, and start a conversation that’s not just about work.
Hi 👋 I’m Jason. I’ve been a remote worker since 2016. Full time remote since 2017, and managing a team remotely since 2018. With people across the world suddenly finding both themselves and their teams homebound, I thought it might be a good opportunity to share some of the things I’ve found helpful as a remote team lead.
I work at Culture Amp, a software platform that helps organisations take action to develop their people and their culture. We have a collection of “inspirations” – ideas you can copy in your organisation to improve its culture. I’ve followed the basic format here.
Basic idea: Book in recurring video “hangouts” where a group of people have a chance to catch up with no set agenda.
Examples:
A team “wind down” each Friday afternoon.
A monthly “remote workers lunch”.
A fortnightly “engineer hangout” for engineers from across the organisation.
These hangouts should be optional to attend.
Why?
When teams aren’t in the same physical location, a common trap is only talking to people during set meeting times, and to only talk about the current project. Having a time to chat about anything, whether or not it’s work related – like you might in an office lunch room – is a chance to build better relationships and foster a sense of belonging.
Instructions:
Pick a group of people who would benefit from a stronger sense of community and belonging. It might be a team, a demographic, or a group with a particular role.
Find the appetite for how often people would like to meet, and for how long. In general, a range between once a week and once a month works for most groups, meeting more often the more important the relationships are. Meeting times can vary between 30 minutes and 2 hours, depending on how much of a “drop in / drop out” vibe you want.
Schedule a time! Try to find a time that is unlikely to be interrupted by other meetings, and unlikely to be highly focused time. Make sure it is within regular office hours to show that you value this type of connection enough to dedicate company time to it. For some groups it may be appropriate to book over lunch
Send an invite! Make sure attendance is optional.
During the hangout:
As the facilitator, make sure you’re online the entire time.
Greet people as they join, and introduce people who might not know each other.
It’s okay if people talk about work. It’s okay if people talk about life outside of work. It’s okay if people don’t talk and seem to be doing work on their laptops.
Ensure there is only one conversation going on at a time. If people want to start a splinter-conversation, they can start a separate video call.
This week at the UX Perth meetup I shared this talk about the human side of building design systems – how your team culture affects the design system you are building, and how the design system can affect the team culture you are building.
At Culture Amp, we operate on a “team of teams” model. We currently have about 200 staff, with about half of those contributing to the product as engineers, designers, product managers, QAs etc. Each product feature has a team responsible for it, and this team is “cross-functional” – so rather than a single infrastructure team, each team should have its own infrastructure specialist. Rather than there being a single design team, each team should have a designer.
The idea is that each team should be able to move to its own priorities without being blocked by other teams. But as you can imagine, this can lead to people being out of sync.
Designers on different teams might be making simultaneous decisions about the styling of a button, and reach two different conclusions, resulting in two button styles.
In other disciplines, like Front End Engineering, you have people from across different teams working on different products with different code-styles (and even different languages!) How do we make sure that people on different teams can produce work that is consistent, high quality, fast to build and easy to maintain?
And then within a team, how can we make sure designers, engineers, product managers and everyone else is speaking the same language, and making decisions from the same framework?
Can we avoid designers saying things like “Use Ideal Sans, size 12px, line height 18px, all caps, and maybe some tighter letter-spacing?” and instead say “Use the Label style”.
Establishing sensible defaults, and giving names to them, enables your team members to talk to each other with less confusion and ambiguity – and that clear communication helps lead to less mistakes and faster work. It also helps product managers know which styles already exist and can be used, and which ones the team needs to invest in creating from scratch.
Across the business, we want to align everyone, so that our product looks and feels consistent, no matter which team built it. And we want to speed up people in all roles on all teams, so that they can spend less effort recreating yet-another-button-component, and focus more on delivering real features that benefit our customers.
This is where design systems really shine: they give a common language that designers, PMs and engineers can use to all be on the same page. They help bring consistency in fonts, colors, styles and components to people on different teams who don’t interact often. And they give us a platform to build common, re-usable designs that can be shared across teams, enabling all the teams to build things faster and with more consistency.
How our company values interplay with our style guide efforts
So building a design system was the right call for us at Culture Amp. But how does that play out with the actual people, each with a specific role on a specific team? How does it affect our approach to work, and more importantly, to team work? How does the design system interplay with our team culture?
At Culture Amp we spend a lot of time talking about our company values, because our aim is to be “Culture First“, to focus on having an amazing work culture, working and living according to a shared set of values, and to let achievement and success arise from that culture.
So we have four values:
Have the courage to be vulnerable
Trust people to make decisions
Learn faster through feedback
Amplify others
How do these values impact our implementation of the design system? And how does our design system feed back into these values? Let’s take a look.
Trusting people to make decisions can be hard. There is a reason micro-managing is such a problem in so many workplaces. And when it comes to design systems, you often hear companies talk about introducing them precisely because they don’t trust people to make decisions. They don’t trust them to use the logo correctly, they don’t trust them to choose an appropriate header type style – so they codify the “correct” way in the style guide and make sure everyone follows it.
Dictatorial decision making doesn’t leave any space for creativity and innovation. I personally believe the most inventive things happen on the edge of a group – not in the center – and you don’t want to squash that by rigid enforcement of a system that takes away a team member’s ability to make a decision.
But more importantly – if you remove all freedom from your team, limiting the ability of your designers to design, and of your engineers to engineer better components, never allowing them to build anything new and better – they’re going to resent it, they won’t enjoy their jobs, and you won’t see their best work – their talents will be wasted.
So how do we balance the desire for consistency with the desire for freedom? Let’s take a look at some examples.
We ask everyone to trust us and stick to the palette. Meanwhile we trust them to make good decisions with how to use that palette, and don’t try to micro-manage through design reviews.
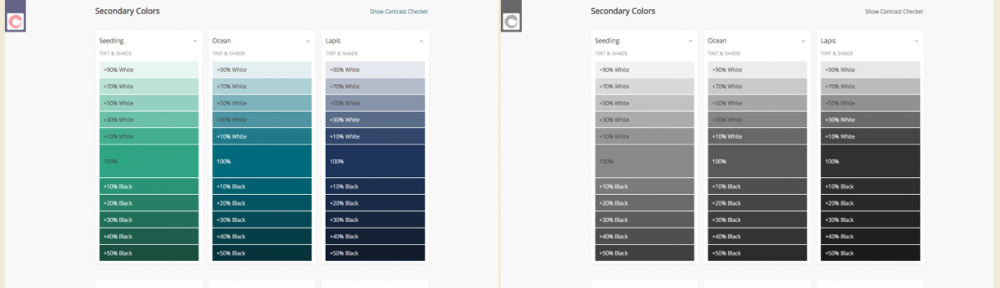
With our brand colors, we have a predefined palette of 3 primary colors (“Coral”, “Paper” and “Ink”), 6 secondary colors (“Ocean”, “Seedling”, “Wisteria”, “Yuzu”, “Lapis” and “Peach”) as well as a small number of tertiary special use colors. These base colors were decided on by designers from across the organisation coming together – it wasn’t an edict from on-high, it was a collaborative effort to unearth the color patterns already in use, and choose and standardise on those that most identified with our brand.
From those colors, we tint them (add white) and shade them (add black) to come up with nearly 300 variations you can use and still be on brand.
With defining this palette, the designers are asking us to trust them – for any text or button or border on the site, we should be able to use one of these colors.
And trust is a two way street.
In return, they can trust us engineers to make sensible choices within the palette. I know the system suggests we use “Ocean” blue for links, and I can choose the appropriate shade of Ocean depending on accessibility requirements, and make the decision myself, without needing to consult a designer.
We trust them to define a palette, they trust us to use it wisely.
We ask people to trust us and stick to these type styles wherever possible. We trust them if they say they need to deviate.
We did a similar thing for type styles, defining a range of headers, paragraph styles, labels and more that could cover most of the usages on a page. (Click here to see our type styles).
While I was giving this talk on Tuesday night I had Slack messages coming in from designers and product managers on one team talking to designers and product managers from our team – how much freedom would their team have to do what they needed for the visualisation they were designing – would they be free to explore or would they be limited to only a small palette of avialable styles?
Again, it comes down to trust. Those building the design system need to trust teams to know when and how to use it, and to know when to step outside it and try something new. If you trust that they share the same goal of great design and consistent design, then you can trust them to make the right call about when to experiment outside of the system. The work this team does may well bubble back up into the design system and become a standard for other teams to share.
One of our other values is “Have the courage to be vulnerable”.
One way this shows up in building a design system is fighting any tendancy towards perfectionism, which is common for many designers and engineers – we want it to be perfect before we share it with the world. We want it to be just right before other teams start using it.
But sometimes sharing it early, even when you still aren’t proud of it yet, or are maybe even ashamed of how it looks or how it’s built, is still a good thing, and can help someone else, even in the early and rough state.
We have a really great mock-up for our design system website with a very pretty way to demo components. But we have to be okay with sharing the ugly version so people can start using it now.
This showed up with launching our design system website, www.cultureamp.design. Parts of it look nice, but no where near as nice as the mock ups. There are designs so beautiful and so on-brand that we really wanted to share them with the world. But perfect can be the enemy of good, and at the end of the day, we had to share this with out team rather than keep it a private secret. We got over our insecurity, and started sharing it, and people have found it useful, even if there’s so much we wish we could improve.
Moving fast and not waiting for perfection means making mistakes, like me needing to make a breaking API change because of a spelling mistake.
This has applied to the components we build as well as the website we use to showcase them. In the interest of moving faster and being less precious, I got excited and shipped a new dropdown component, including the ability to add a “seperator” to the menu. Not a “separator”. Yes I shipped a version of our design system with a spelling mistake, and fixing that was a breaking change, immortalised forever as a version bump in our CHANGELOG.
Putting yourself out there isn’t only about sharing your work early. It’s also about opening up the possibility for them to criticise the work you’ve done. Sometimes asking for feedback gives you feedback you didn’t want to hear.
We did this when our team, who are the main drivers of the design system, asked designers and front-end engineers from across the company for feedback on how we’re going.
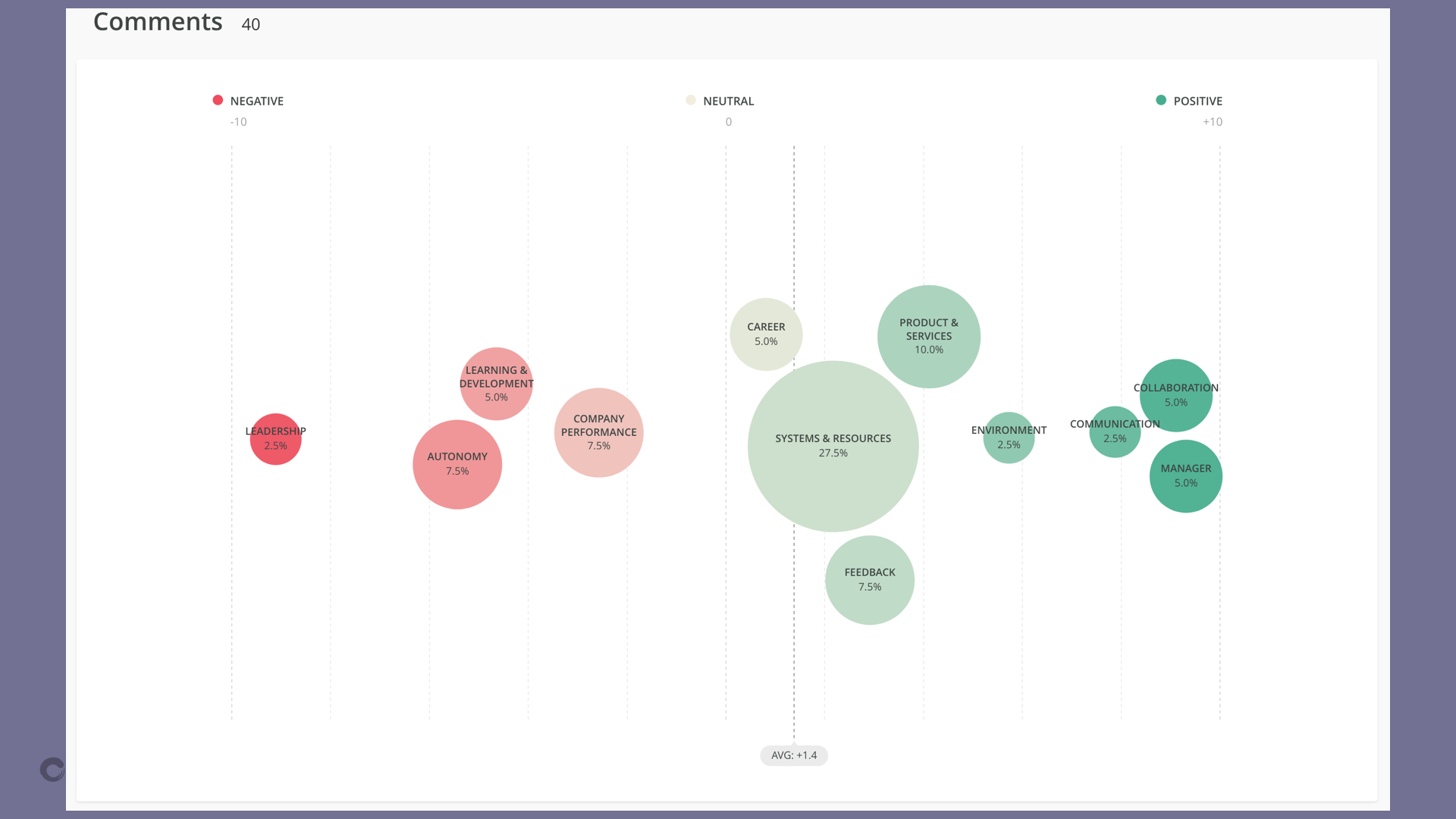
A visualization of the comments we received when we asked for feedback on how our team was going
Often we talk about user experience and user centered design, but with design systems, we have two classes of users: the end users of our product, and our colleagues who use the design system to build the product. Taking the time to listen to this second group, our colleagues and team-mates, is crucial.
And it ties into one of our other company values: Learn faster through feedback.
One key thing we learned through this survey was that we’d been over-investing in the base level styles (typography, color, icons) and underinvesting in the mid-level components (for example drop down menus, tabs, and select boxes).
We spent all our time on Styles, but the feedback showed we would be more helpful if we built more ready-to-use components.
Our team had been focusing on bringing consistency at the low level – changing typefaces and background colors and icons across the app, which was an enormous amount of effort on our part. But what would have helped the other teams more is if we built components that helped them deliver their designs faster. It might mean it would take longer to bring consistency to some of these fundamental styles, but it would mean that these teams are delivering valuable features to customers sooner.
That message came through our survey, loud and clear.
And at the end of the day, that ties into our fourth value:
Amplifying others. That’s the reason we’re building a design system in the first place – it allows us to amplify each of the product teams in our company, allowing them to move faster, stay in sync, spend less time sweating the fine details – and deliver a higher quality and more consistent experience to our customers.
That’s what it’s all about – and if we keep this in mind while we build out our system, it can help keep the work grounded, practical, and more likely to make an impact.
It isn’t about having the prettiest showcase of components. It isn’t about the elegance of your solutions, or the way you ship new components to your teams. At the end of the day, it’s about the people in your teams, and how you can amplify them, so they can build better products, faster, and with less stress.
And if amplifying your workmates does not motivate you, then you might have bigger team culture issues that a design system is not going to fix!
Have any questions? Feedback? Other observations on how team culture and design systems interplay? I’d love to hear them!
Adding the `filter: grayscale(1)` CSS rule is an easy way to notice places your design is too dependent on colour
This is the blog post version of a talk I gave at the Perth Web Accessibility Conference. I also repeated the talk at a “BrownBag” team lunch at Culture Amp, which you can watch here, or you can read the blog-post version below. I’ve got a live example (open source! try it yourself!) at the end of the post.
On the front-end team at Culture Amp, we’ve been working on documenting and demonstrating the way we think about design, with a design system – a style-guide and matching component library for our designers and developers to use to make our app more consistently good looking, and more consistently accessible.
But first, a story.
Here’s a photo of me, my older sister, and younger brother:
Me at the back, my sister and brother in the front
Me and my brother are both red-green color blind. Most of the time color-blindness isn’t a big deal and compared to other physical limitations, it doesn’t usually make life difficult in any significant way.
But growing up, my brother Aaron really wanted to be a pilot. Preferably an air-force pilot, like in Top Gun. But for a generation that grew up with every TV show telling us “you can be anything if you try hard enough”, there was a footnote: anything except a pilot. He couldn’t be a pilot, because he was red / green color blind. The air-force won’t even consider recruiting you for that track. They’ll write you off before your old enough to join the air cadets.
Why? Because the engineers who designed the cockpits half a century ago made it so that the only way you could tell if something changed from safe to dangerous was if an LED changed from green to red. So people with red-green color-blindness were out, and my brother was told he couldn’t be a pilot.
Cockpits have lots of small controls, and some of them rely purely on red/green color distinction to be read accurately.
Now, becoming an air-force pilot is super-competitive, and he might not have made it anyway, but to have your dream crushed at the age of 10, because an engineer built a thing without thinking about the 8% of males who are red/green color blind, is pretty heartbreaking.
Luckily, as web professionals we’ve got a chance to create a digital world that is accessible to more people, and is a more pleasant experience, than much of the real world. We just have to make sure it’s something designers and developers are thinking about, and something they care about.
So, design systems
One of the big lessons we’ve learned in the web industry over the last few years is that if you want your site, product or service to leave a lasting impression, it’s not enough to do something new and shiny and different. What’s important to a lasting impression is consistency: consistency builds trust, and inconsistency leads your users into confusion and frustration and disappointment.
It’s true of your branding, it’s true of your language and tone, it’s true of your information architecture, and it’s especially true of your commitment to creating accessible products and services. For example if your landing page is screen-reader friendly but your product is not, you’re going to leave screen-reader users disappointed. Consistency matters.
But as a company grow, consistency gets harder. It’s easy to have a consistent design when you have a landing page and a contact form. It’s harder when you have a team of 100 people contributing to a complex product.
The Culture Amp team has experienced those growing pains – we’ve grown from 20 employees three years ago to over 200 today, almost half of them contributing to the product – and it’s easy to lose consistency as users navigate from page to page and product to product. The UI built by one team might feel different and act differently to the UI built by another team.
So we started looking into design systems.
The Salesforce “Lightning Design System” showed how a strong design system can bring consistency to a whole platform, even with 3rd party developers
Design systems are a great way to bring consistency. By documenting the way we make design decisions, and demonstrating how they work in practice, we can help our whole team come together and make a product that looks and feels consistent – and that consistency is the key to a great experience for our users.
As we codify our design thinking we are lifting the consistency of our app – not just of our branding and visual aesthetics, but of our approach to building an accessible product.
Culture Amp’s approach to color
So we’re a start-up, with three overlapping product offerings build across half a dozen teams. And we want to make that consistent.
One way to do that would be to have a design dictator who approves all decisions about color usage, making sure they’re on-brand and meet the WCAG contrast guidelines. But one of our company values is to “Trust people to make decisions”, and that means trusting the designers and front-end engineers in each team to make the right call when it comes to picking colors for the screens they are in.
How do we let them make the call, but still ensure consistency?
Well, as a group our designers worked together to define the palette they would agree to use. They consisted of three primary colors (Coral, Paper and Ink), six secondary colors (Seedling, Ocean, Lapis, Wisteria, Peach, Yuzu), as well as Stone for our standard background.
Our color system starts with 3 primary colors and 6 secondary colors. I have no idea how the team picked the color names…
Every color on the page should be one of the colors on the palette.
But what about when you need it slightly lighter or slightly darker? When you need more contrast, or want just a slight variation? We allow designers to use a color that is derived from the original palette, but with a tint (white mixed in) or a shade (black mixed in).
We can actually figure these tints and shades out programmatically, using SASS or Javascript:
(The embed here demonstrating programmatically generating colour palettes no longer works, sorry)
(Note: the SASS code is even easier. You can use the lighten() or darken() functions, or the custom mix() function if you’d prefer to tint or shade with a custom color. All three of these functions are built in.
So now we have three primary colours, and six secondary colours, and computationally generated tints and shades for each in 10% increments, resulting in 171 colour variations, which all fit with our brand. Woo!
By adding tints and shades to our base colors, we can generate a flexible but consistent color palette
This range gives enough freedom and variety to meet individual teams needs on a page-by-page basis, while still bringing consistency. Designers are free to move within this system and make the right decision for their team.
So what about color contrast?
Currently Culture Amp has committed to complying with WCAG AA standard contrast ratios. This means the contrast between the text color and the background color must be at least 4.5 for small text, and at least 3.0 for large text. (If we wanted to go for WCAG AAA standard contrast ratios, those values 7.0 and 4.5 respectively).
How do we get the designers and developers on our team thinking about this from the very beginning of their designs? We could audit after the designs after-the-fact, but this would be frustrating for designers who have to revisit their design and re-do their work. Making people re-do their work is not a way to win friends and advocates for your color contrast cause.
<Note: I had an embed here, that demonstrated auto-generated colour palettes, but it no longer works>
So we can actually check whether our colors will be able to hold white or black text with a sufficient contrast ratio. And because we derive our color values programmatically, we can check if all 171 of our derived color values are accessible with large text or small text, black text or white text, and display all of that information at a glance:
We can programmatically check contrast, and show at a glance which colors support white text or black text at small and large sizes.
Now our designers can come to this page, explore every color within our palette, and at a glance know which of these colors will be able to display text with sufficient contrast to be considered accessible.
For bonus points, we can also programmatically determine if a background color would be better suited to have text colored white or black:
<Note: I had an embed here, that demonstrated auto-generated colour palettes, but it no longer works>
If you build it, they probably won’t come
So we’ve made a great page where designers can explore our palette colors, and at a glance gain an understanding of which combinations will have sufficient contrast. But by this point everyone in the software industry should hopefully know that “if you build it, they will come” is simply not true. If you want people to engage with your design system – or with anything you’ve built – you need to offer something of value, you need to solve a real problem for them.
So how do we get the designers and developers across our different teams to care enough to come look at this page? We need to offer them some convenience or solve a problem they have.
What are the most common things our team needs help with when thinking about our brand colors? They usually want to explore the range of the palette, and then find a HEX code or a SASS variable to start use that color.
People on the team need to know what the brand colors are. Now we can send them to this page, and they’ll see the accessibility info as a bonus.
We have a dropdown that lets our team copy/paste the colour values so they can use them in their design tools or their code
So we tried to make our design system colors page as helpful as possible, providing a way to explore the colors, see the shades and tints, see what colored text it best pairs with, and copy color values to your clipboard.
Next time someone needs to reference our brand colors, this feature set means they’ll come to our design system page first, because they know they can explore the colors, and get the correct codes in whatever format they need. We’re solving a problem for them, and, while we have their attention, using the opportunity to inform get them thinking about color contrast and accessibility.
What else?
So we’re just getting started on our journey of using design systems to improve the consistency of our design and our accessibility. But color contrast is a great place to start, and it’s already making me think about how we can use the design system project to put accessibility front-and-center in the design culture of our team.
The web’s most popular component library, Bootstrap, solves a problem for designers and developers by allowing fast prototyping of common website elements, but by offering components with accessibility concerns baked in, and by encouraging good accessibility practice in their documentation, they’ve used their design system to lift the level of accessibility on millions of websites.
Bootstrap was one of the first open source component libraries, and works hard in its documentation to encourage accessible use of its components.
If you have other ideas on how design systems could be used to bake accessibility into your team culture and product design, I’d love to hear about it! It’s an exciting project to be part of, raising the design consistency and the accessibility consistency across the various products offered at Culture Amp.
If you’d like to join us, Culture Amp is hiring front end developers – either in Melbourne, or remote within Australia. It’s an amazing place to work, I’d encourage you to apply. See the Culture Amp Careers page for more info.
Bonus #1:
Our whole Color Showcase component is now available open source. You can view the Color System Showcase repo on Github or even try embed it online by entering JSON code on this page. (Sorry, this link no longer works).
Here’s a live iframe preview with Culture Amp colors inserted:
Bonus #2:
If you want to test how your site would look to a completely color-blind person, you can type this into the browser console:
document.body.style.filter="grayscale(1)";
Try it!
Adding the `filter: grayscale(1)` CSS rule is an easy way to notice places your design is too dependent on colour
I’ve been using Haxe for a long while, and for about 2-3 years I was using Haxe full time, building web applications in Haxe, so I know how important managing your dependencies is, and I know how painful it was with Haxelib, especially if you had a lot of dependencies, a lot of projects, or needed to collaborate with people on different computers.
Haxelib is okay when you’re just installing one or two libraries, and they’re libraries with stable releases where you don’t change versions often, and if you don’t need to come back to your code after long gaps in time. Basically, haxelib is fine if you’re doing weekend hackathons or contests like Ludum Dare where your projects probably aren’t too complex, you’re not collaborating with too many other people, you’re using existing frameworks, and you don’t have to worry about if it will still work fine in 4 months time. Otherwise, it can be quite painful.
I tried to help with Haxelib at one point in time (I still am in the top 4 contributors on Github, most of that was back in 2013 though), but it proved pretty unruley – even skilled developers were afraid of changing too much or refactoring in a way that might break things for thousands of developers. And some changes were impossible to make without first changing the Haxe compiler. So it’s largely sat in the “too hard” basket and has not had many meaningful improvement since it first became it’s own project in 2013.
(No offense to anyone who has been working on it – you are a braver soul than I! But I think we all agree it’s not as good as it needs to be.)
Since mid 2016, I have been working in other jobs where I don’t use Haxe full time, instead spending more time with JS: using tools like NPM, Yarn, Webpack. And they’re certainly not perfect when it comes to dependency management, but there are a few things that they do right (Yarn especially).
Part 2: What the JS ecosystem gets right.
In Node JS land (and eventually normal JS land), there was a package manager called NPM – Node Package Manager. It had a registry of packages you could install. It would also let you install a package from Github or somewhere else. The basic things.
Here’s what I think it did right:
Used a standard format (package.json) to describe which packages a project uses.
Put all of the libraries in a standard location (node_modules/${my_cool_lib}/)
NodeJS didn’t care if you used NPM or not. As long as your stuff was in node_modules, it would be happy.
Why was this a good move? Because it allowed some talented people to build a competitor to NPM, called Yarn. By having simple expectations, you can have two competing package managers, and innovation can happen. Woo!
Yarn is what I use at work on a big project with 119 dependencies (and about 1000 sub-depedencies). Here’s what yarn did right:
Reproducible builds. While package.json has information about which version I want (say, React 16.* or above), Yarn would keep information in a file called yarn.lock which says exactly which version I ended up using (say, React 16.0.1). This was when my friend joins the project and tries to install things she won’t accidentally end up on a newer or older version than me – Yarn makes sure we’re all using exactly the same version, and all of our dependencies and sub-dependencies are also exactly the same.
A global cache. When Yarn came out, it was several times faster than NPM on our project because it kept a cache of dependencies and was able to resolve them quickly when switching between projects and branches. NPM has caught up now – but that’s the benefit of competition!
Part 3: Introducing lix (and its friends: switchx and haxeshim)
In 2015 I remember chatting to my friend Juraj Kirchheim (also one of the key contributors who just kind of gave up) about what an alternative might be, and he described something that sounded great, a futuristic utopian alternative to haxelib.
2 years later, and it turns out, it’s been built! And it’s called “lix”.
(What’s with the name? I’m guessing it is short for “LIbraries in haXe”, a leftover from when every Haxe project needed an X in it for cool-ness, and Haxe was spelt as haXe. That, and the lix.pm domain name must have been available).
Lix also depends on two other projects: haxeshim and switchx. The names aren’t super obvious, so here is my understanding of how it all works:
Haxe Shim intercepts calls to Haxe and does some magic. The Haxe compiler on it’s own explicitly calls haxelib, so you literally can’t replace haxelib without intercepting all calls to the compiler and getting rid of -lib arguments. So haxeshim is a shim that intercepts Haxe calls and sorts out -lib arguments so that haxelib is never needed.
As a bonus, it also supports switching to the right version of Haxe for the current project. But for that, we also need “switchx”.
SwitchX lets you pick the Haxe version you need for your project, and automatically switches Haxe versions for whatever project you’re in. If you change between project A, on Haxe 3.4.3, and project B, in a different folder and running Haxe 4, it will always use the correct one.
How?
When you start a project you run switchx scope create. This makes a .haxerc file which says that this folder is a specific project, or “scope”, and should use the Haxe version defined in the .haxerc file.
How do you change the version?
You run switchx use latestor switchx use stable or switchx use nightly or switchx use 3.4.3 etc. It lets you instantly switch between different versions, and for the correct version to always be used while you’re in your project folder.
Nice!
Lix is a package manager that you use to install packages. It is made to work with Haxe Shim, and creates a “haxe_libraries” folder, with a new hxml file for each dependency you install. It’s super fast because it uses a global cache (like yarn) and it makes sure you always have the correct version installed (like yarn). It supports installing dependencies from Haxelib, Github, Gitlab or HTTP (zip file). Anytime you update or change a dependency, one of the haxe_libraries/*.hxml files will be updated, you commit this change to Git, and it will update for all of your coworkers as well. Magic.
These tools are (for now) built on top of NodeJS, so you can install them with NPM or Yarn.
If you want to install each of these, you basically run these commands (warning: these will replace your current Haxe installation):
# Install all 3 tools and make their commands available.
yarn global add haxeshim switchx lix.pm
# Create a ".haxerc" in the current directory, informing haxeshim that
# this project should use a specific version of Haxe and specific
# `haxe_libraries` dependencies
switchx scope create
# Use the latest stable version of Haxe in this project.
switchx install stable
Part 4: What lix can do that haxelib cannot do (well).
With this setup, here’s what I can do that I couldn’t do before:
Be certain that I always have the exact right version installed, even if the project is being set up on someone else’s machine. Even if I pulled from a custom branch, using something like lix install github:haxetink/tink_web#pure (install the latest version of tink_web from the “pure” branch), when I run this on a different machine, it will use not only the same branch, but the exact same commit that it used on my machine, so we will be compiling the exact same code.
Easily get up and running on a machine where they don’t even have haxe installed. I tried this today – took a project on Linux, and set up its dependencies in Lix. It used a combination of Haxelib, Github, Gitlab, and custom branches. It was a nightmare with Haxelib. I also added haxeshim, switchx and lix.pm as “devDependencies” so they would be installed locally when I ran yarn intall. I opened a Windows machine that had Git installed, but not haxe, cloned the repo, and yarn install. It installed all of the yarn dependencies, including haxeshim, switchx, and lix, and then running lix download installed all of the correct “haxe_libraries”, and then everything compiled. Amazing!
Know if I’ve changed a dependency Today I was working on a change for haxe-react. In the past I would have used haxelib dev react /my/path/to/react-fork/. Now I edit haxe_libraries/react.hxml and change the class path to point to the folder my fork lives in. The great thing about doing this is, Git notices that I’ve changed it. And so when I go to commit the work on my project, git lets me know I’ve got a change to “react.hxml”, I’ve changed that dependency. In this case, I knew what to do: push my fork to Github, and then run lix install gh:jasononeil/haxe-react#react16 to get Lix to properly register my fork in a way that will work with my project going forward. I then commit the change, and people who use my project will get the up-to-date fork.
Start a competing package manager The great thing about all of this, is that “lix” has some great features, but if I want to write better ones, I can. Because of the way “haxeshim” just expects dependencies to haxe a “haxe_libraries/*.hxml” file, I could write my own package manager, that does things in my own way, and just places the right hxml file in the right place, and I’m good to go. This makes it possible to have multiple, competing package managers. Or even multiple, co-operating package managers.
Part 5: Vote on the future
So, I think Lix has learnt from a lot of what has gone “right” in the NodeJS ecosystem, and built a great tool for the Haxe ecosystem. I love it, and will definitely be using it in my Haxe projects going forward.
The question is, do we really need “haxeshim” and “switchx” and other such tools just in order to have a competing package manager? For now sadly, because of the way haxe and haxelibare tied at the hip, you do need a hack like this. But there’s a discussion to change that. (See here and here).
If you care about Haxe projects having maintainable dependency management, you can help by voting up comments in a discussion that’s happening right now. Here are the comments that I think will help Haxe support something like Lix, and more competing package managers, as first class citizen going forward. Feel free to upvote with a thumbs up emoji:
Feel free to have a look and contribute to the discussion. For now though – if you don’t mind installing haxeshim and switchx, there is a very good solution for managing your haxelibs and dependencies in a reliable, consistent, but still flexible way. And it’s called Lix.
Update: I ended up getting a new job which came with a new laptop, so don’t have the XPS 9365 anymore. I hope this post is still helpful to people but I won’t be able to provide any more support. The official Fedora support page is over here: http://ask.fedoraproject.org/ Good luck everyone!
While having breakfast on Friday morning, my 5 year old laptop was going fine. Then Firefox froze. I pressed alt-tab, nope, everything is frozen except the mouse. Then the mouse was frozen. Then I reset the computer, and got this message “Operating System Not Found”. My hard drive had died.
Rather than spend a weekend fiddling to repair it, I decided to spend my tax-return money to buy a new laptop – a Dell XPS 13 9365 2-in-1. Fancy as! But, whenever you buy a fairly knew and fancy laptop, less than 12 months old, with the intent to install Linux – you should probably set aside some time because you just know there’s going to be issues.
One weekend later, I’m the happy owner of a XPS 13 2-in-1 running Fedora 26. Here’s all the tips and gotchas and cry-into-a-pillow moments that I had to get through to make it this far.
Trying Fedora instead of Ubuntu
Before I made the purchase, I was doing some Googling to see if Ubuntu would even load on an XPS 13 9365. The verdict seemed to be that it would load, but there was some difficulty getting suspend/resume to work, but it was possible. I decided to go ahead with the purchase. But in my reading, I came across this comment:
I was unable to uninstall Ubuntu on the XPS at all. And out of frustration I tried Fedora and I was simply BLOWN away by the polish. And today we have Fedora 26 that is even better. I am semi-validated by Ubuntu moving to Gnome as well. Ubuntu was simply too unpolished with Mir + Unity.
I decided to give Fedora a go. Now that most of my development work happens in Docker, I’m not too worried about which distro I have running on bare-metal – and I’m up for trying something new!
Verdict: I’ve enjoyed Fedora – the polish in Fedora 26 really is there compared to Ubuntu 16.04 (admittedly – it is 12 months newer so that is to be expected).
To get started with Fedora, download the “Fedora Media Writer” which will prepare a Live USB for you. See the Fedora installation guide for more info.
Shrinking a Windows Partition is beyond my pay-grade
At first I was interested in keeping Windows 10 installed and dual booting, because it might be nice to occasionally see test how it works etc. But part of the dual-boot process involves resizing the Windows partition to make space for Linux.
I had a 460GB Windows partition, with 30GB used. For the life of me I couldn’t shrink it smaller than 445GB – leaving only 15GB for Linux. I tried following different tips, tricks and tutorials for about 30 minutes, and then decided that I’ve lived without Windows for a decade, I can keep going without it now.
SATA mode has to be AHCI
By default the 9365 has it’s SATA hard drive configured to be in “RAID” mode rather than “AHCI”. To be able to install Fedora, I needed to change this to AHCI. Not sure why. Here’s a question / answer that prompted me to make the change.
It’s worth noting that if you intend to dual boot, changing from “RAID” to “AHCI” can cause serious problems for Windows unless you do some prep work first. You can change it and change back, but if you want to dual boot, you will need both to be on AHCI.
A painful firmware bug (that makes you think your laptop is dead forever)
This bug had me thinking my laptop was bricked and would need to be sent for warranty. It would literally sit on the DELL logo for what felt like forever, but turned out to be 5 to 10 minutes. I can’t explain how relieved I was to read a blog post where someone described the same symptoms:
When changing the SATA drive setting from RAID to AHCI, and disabling the “Secure boot” option in the BIOS (both actions are needed to install Ubuntu), the booting process gets stuck in the Dell logo for a long time, around 5 minutes, before it makes any progress. Even trying to enter the BIOS again to change those settings makes me have to wait that long.
Also, when booting when those settings on and entering the BIOS, the whole user interface of the BIOS menu, even just moving the mouse cursor around, is extremely slow. Clicking on a menu option on the BIOS makes the screen refresh to the next screen with a very slow transition of about 3 seconds.
I’m have upgraded to the latest BIOS firmware as of April 8, 2017 (Version 01.00.10, 3/9/2017). This bug is currently preventing me from setting up a dual-boot mode with Windows 10 + Ubuntu, which makes the system not usable for my specific use cases. I’d really appreciate if these issues could be resolved soon.
The fix:
You can’t have “SATA MODE = AHCI” and “SECURE BOOT = FALSE” at the same time.
Because “SATA MODE = AHCI” is required for a Fedora install, we need “SECURE BOOT’ to be true. Turns out, this is actually okay.
One final thing to do in BIOS: configure it to boot from USB.
Because we’re using SecureBoot, this is not as straight forwarded as choosing an option from a boot menu.
Steps:
Ensure “Disable Legacy Boot ROMs” is ticked. It will need to be ticked for secure-boot to be ticked.
Ensure “Secure Boot” is ticked. It’s on a different page in the settings.
Ensure “Boot mode” is “UEFI” not “Legacy”.
This will show a list of boot options. The terrible GUI interface will require you to scroll down to find the “Add Boot Option” button. Click it.
Add a boot option named “Fedora” and click the “…” to open the file browser.
Find your USB drive in the list (mine was named “Anaconda” by the Fedora Media Writer).
Load the file “/EFI/BOOT/grubx64.efi“
Save the new boot item. Use drag and drop to move it to the top, so it has the highest priority.
Save your settings, and restart – and hopefully – Fedora will load up and kick into Live CD mode.
Before you install
Before I hit install, I did a quick check:
Wifi works: yes
Sound works: yes
Touchscreen works: yes
Webcam works: yes
Suspend / Resume works: no. Bummer – but my research had suggested this was probably going to be an issue, so I continued anyway.
In the install options I deleted the Windows 10 partition, and got it to auto-partition from there. Then hit install. Woo!
Getting suspend and resume to work.
**Update:** It turns out I’m still having supend/resume issues. I think figuring out how to install the 4.13 version of the kernel while SecureBoot is enabled is what I will need.
After the install, almost everything worked as expected, and the whole experience was really nice – it’s a beautiful laptop, and the new version of Fedora with Gnome 3 is quite pleasant. Until you close the lid and it suspends. Because then it won’t wake up again.
What would happen:
The screen would go dark, but the keyboard backlight would stay on.
Pressing the tiny power button on the side of the case does nothing at first.
If you keep holding the power button for like 10 seconds, the login screen lights up, and everything is still there, but the moment you let go, it suspends again.
If you hold it down long enough, it eventually turns off. You’ll need to do this to get out of the broken suspend, but it takes forever and feels like you’re pressing the little power button so hard you’ll break it.
[jason@jasonxps enthraler]$ uname -a
Linux jasonxps 4.11.8-300.fc26.x86_64 #1 SMP .....
I read a bunch of Q&A suggestions on tips for getting this to work, but none helped that much – reading through the bug report above though convinced me that I needed to upgrade from 4.11 to 4.12 or 4.13.
Upgrading to the very latest kernel (4.13-rc4) seems easy, but as the wiki page notes, it won’t work with SecureBoot – so that turned out to be a dead end for me. (Signing the kernel for SecureBoot might be possible, but I couldn’t be bothered learning enough to understand the tutorials).
4.12 isn’t released yet, but it’s supposed to be in testing. Unfortunately, enabling the “updates-testing” repository and running “dnf upgrade” didn’t install the new kernel. I’m not sure if it was supposed to.
Be careful here that you don’t override the kernel you’re currently using. You may need to add options to “dnf” if it suggests that it’s going to remove the package for the kernel you’re currently on.
After restarting, test that the new kernel is working:
[jason@jasonxps enthraler]$ uname -a
Linux jasonxps 4.12.5-300.fc26.x86_64 #1 SMP ...
And now, you can close the lid and expect it to suspend and resume. For me, I still have to hold the power button for like 6 seconds to get it to resume, but hey, at least it comes back. I’m hoping 4.13 will come out and fix that problem too.
Note – I also changed the setting in Gnome Power Settings for “When the Power Button is Pressed” from “Suspend” to “Nothing”. Reason: sometimes holding down the power button that long to resume it would then trigger another “supsend”. So I set the button to do nothing. I can just close the lid to supsend.
Ubuntu Unity-like keyboard shortcuts
Overall I’ve really enjoyed Gnome 3 over Ubuntu Unity. One thing I missed though was being able to press “Win+1” to open my file manager, “Win+2” to open Firefox, “Win+3” to open Visual Studio Code, “Win+4” to open Chrome etc. Basically, my most common applications all sit in the dock on the left, and I can use a quick keyboard shortcut to switch to that app – and if it’s not open already, it will open it. Gnome doesn’t have this by default.
Well, that was certainly not something I’d trust my Grandma to complete successfully. But hey – at least it works. If I learn any new tricks for getting Fedora to run nicely on a Dell XPS13 9365 2-in-1, I’ll post here.
If you have any questions, feel free to ask – no guarantees I’ll be able to help though :)
Once you have more than one project you’re building in Haxe, you tend to run into situations where you use different versions of dependencies. Often you can get away with using the latest version on every project, but sometimes there are compatibility breaks, and you need different projects to use different versions.
There is a work-in-progress issue for Haxelib to get support for per-project repositories. Until that is finished, here is what I do:
cd ~/workspace/project1/
mkdir haxelibs
haxelib setup haxelibs
haxelib install all
And then when I switch between projects:
cd ~/workspace/project2/
haxelib setup haxelibs
What this does:
Switch to your current project
Create a folder to store all of your haxelibs for this project in
Set haxelib to use that folder (and when I switch to a different project, I’ll use a different local folder).
Install all the dependencies for this project.
Doing this means that each project can have it’s own dependencies, and upgrading a library in one project doesn’t break the compile on another project.
Hopefully that helps someone else, and hopefully the built in support comes soon!
So far so good. But what if we have a 3rd user class, “Moderator”, that actually has a constructor that requires 3 arguments, not just the username and password.
createUser( Moderator, “bernadette”, “mypass” );
This compiles okay, but will fail at runtime – it tries to call the constructor for Moderator with 2 arguments, but 3 are required.
My first thought was, can we use an interface and specify the constructor:
interface IUser {
public function new( user:String, pass:String ):Void
}
Sadly in Haxe, an interface cannot define the constructor. I’m pretty sure the reason for this is to avoid you creating an object with no idea which implementation you are using. Now that would work for reflection, but wouldn’t make sense for normal object oriented programming:
function createUser( cls:Class<IUser>, u:String, p:String ) {
var u:IUser = new cls(u,p); // What implementation does this use?
}
So it can’t be interfaces… what does work? Typedefs:
typedef ConstructableUser = {
function new( u:String, p:String ):Void,
function save():Void
}
And then we can use it like so:
function createUser( cls:Class<ConstructableUser>, u:String, p:String ) {
var u:ConstructableUser = Type.createInstance( cls, [u,p]);
u.save();
}
createUser( StaffMember, “jack”, “mypass” );
createUser( Subscriber, “aaron”, “mypass” );
createUser( Moderator, “bernadette”, “mypass” ); // ERROR – Moderator should be ConstructableUser
In honesty I was surprised that “Class<SomeTypedef>” worked, but I’m glad it does. It provides a good mix of compile time safety and runtime reflection. Go Haxe!
`AcceptEither`, a way to accept either one type or another, without resorting to “Dynamic”, and still have the compiler type-check everything and make sure you correctly handle every situation.
I just posted a quick gist to the Haxe mailing list showing how one way that abstracts work.
They’re a great way to wrap a native API object (in this case, js.html.AnchorElement) without having to create a new wrapper object every single time. Which means they’re great for performance, the end result code looks clean, and thanks to some of the other abstract magic (implicit casts, operator overloading etc) there is a lot of cool things you can do.
Have a look at the sample, read the Haxe manual, and let me know what you think or if you have questions :)
A while ago I posted about neko.web.cacheModule, a way to make your site run dramatically faster on mod_neko or mod_tora. After spending some time making ufront compatible with this mode of running, I was excited to deploy my app to our schools with the increased performance.
I deployed, ran some tests, seemed happy, went home and slept well. And woke up the next morning to a bunch of 501 errors.
The Error
The error message was coming from the MySQL connection: “Failed to send packet”.
At first I just disabled caching, got everyone back online, and then went about trying to isolate the issue. It took a while before I could reproduce it and pinpoint it. I figured it was to do with my DB connection staying open between requests, thanks to the new module caching.
A google search showed only one Haxe related result – someone on IRC that mentioned when they sent too many SQL queries it sometimes bombed out with this error message. Perhaps leaving it open eventually overran some buffer and caused it to stop working? Turns out this was not the case, I used `ab` (Apache Benchmark tool) to query a page 100,000 times and still didn’t see the error.
Eventually I realised it was to do with the MySQL Server dropping the connection after a period of inactivity. The `wait_timeout` variable was set to 28800 by default: so after 8 hours of inactivity. So long enough that I didn’t notice it the night before, but short enough that the timeout occured overnight while all the staff were at home or asleep… So the MySQL server dropped the connection, and my Haxe code did not know to reconnect it. Whoops.
The Solution
I looked at Nicolas’s hxwiki source code, which runs the current Haxe site for some inspiration on the proper way to approach this for `neko.Web.cacheModule`. His solution: use http://api.haxe.org/sys/db/Transaction.html#main. By the looks of it, this will wrap your entire request in an SQL transaction, and should an error be thrown, it will rollback the transaction. Beyond that, it will close the DB connection after each request. So we have a unique DB connection for each request, and close it as soon as the request is done.
My source code looks like this:
class Server
{
static var ufApp:UfrontApplication;
static function main() {
#if (neko && !debug) neko.Web.cacheModule(main); #end
// Wrap all my execution inside a transaction
sys.db.Transaction.main( Mysql.connect(Config.db), function() {
init();
ufApp.execute();
});
}
static function init() {
// If cacheModule is working, this will only run once
if (ufApp==null) {
UFAdminController.addModule( "db", "Database", new DBAdminController() );
ufApp = new UfrontApplication({
dispatchConfig: Dispatch.make( new Routes() ),
remotingContext: Api,
urlRewrite: true,
logFile: "log/ufront.log"
});
}
}
}
My token one day a week I continued on my Node-Webkit project. This time I made externs for Kue (externs, which appear to be working) and FFMpeg (externs, not functional just yet). Still enjoying working with Node-Webkit, and with the Node-API library especially. Sad I didn’t get to make more progress on it this week.
Ufront:
Make tracing / logging work reliably between multiple requests. After enabling neko.Web.cacheModule(), I began to find areas where Ufront was not very multiple-request-friendly. These would have surfaced later with a port to Client JS or Node JS, but it’s good to find them now.One problem was that our tracing and logging modules were behaving as if there was only one request at a time. This could result in a trace message for one request ending up being output to somebody else’s request, which is obviously bad.
The problem is a tricky one, as trace() always translates to haxe.Log.trace(), and you with Ufront’s multiple-request-at-a-time design, you can’t know which request is the current one from a static method. If I think of a clever way to do it, possibly involving cookies and sessions, then I might include a HttpContext.getCurrentContext() static method. This would probably have to be implemented separately for each supported platform.
The solution for now, however, was to not keep track of log messages in the TraceModule, but in the HttpContext. Then on the onLogRequest event, the trace modules get access to the log messages for the current context, and can output them to the browser, to a file, or whichever they choose.
The downside is that you have to use httpContext.ufTrace() rather than trace(). I added a shortcut for this in both ufront.web.Controller and ufront.remoting.RemotingApiClass, so that in your controllers or APIs you can call uftrace() and it will be associated with the current request. There is also ufLog, ufWarn and ufError.
I also made RemotingModule work similarly with tracing and logging – so logs go to both the log file and the remoting call to the browser.
Fix logging in ErrorModule. One of the things that made debugging the new ufront really hard was that when there was an Error, the ErrorModule displayed, but the trace messages did not get sent to the browser or the log file. I did a bit of code cleanup and got this working now.
Fixed File Sessions / EasyAuth. Once able to get my traces and logs working more consistently, I was able to debug and fix the remaining issues in FileSession, so now EasyAuth is working reliably, which is great.
Added Login / Logout for UF-Admin. With UF-Admin, I added a login screen and logout, that works with EasyAuth for now. I guess I will make it pluggable later… For now though it means you can set up a simple website, not worry about auth for the front end, but have the backend password protected. If you use EasyAuth for your website / app, the same session will work on the ufadmin page.
Created uf-content for app-generated files. I moved all app-generated files (sessions, logs, temp files etc) into a folder called “uf-content”. Then I made this configurable, and relative to httpContext.request.scriptDirectory. You can configure it by changing the contentDirectory option in your UfrontConfiguration. This will make it easier when deploying, we can have instructions to make that single directory writeable but not accessible via the web, and then everything that requires FileSystem access can work reliably from there.
Pushed new versions of the libraries. Now that the basics are working, I pushed new versions of the libraries to Haxelib. They are marked as ufront-* with version 1.0.0-beta.1. From here it will be easy to update them individually and move towards a final release.
Demo Blog App. To demonstrate the basics of how it works, and a kind of “best practices” for project structure, I created a demo app, and thought I would start with a blog. I started, and the basic setup is there, including the config structure and each of the controller actions, and the “ufadmin” integration. But it’s not working just yet, needs more work.
Identified Hair website. I have a website for a friend’s small business that I’ve been procrastinating working on for a long time. On Saturday I finally got started on it, and set up the basic project and routes in Ufront. In about 4 hours I managed to get the project set up, all the controllers / routes working, all the content in place and a basic responsive design with CSS positioning working. All the data is either HTML, Markdown or Database Models (which get inserted into views). Once I’ve got their branding/graphics included, I’ll use ufront to provide a basic way to change data in their database. And then if they’re lucky, I might look at doing some Facebook integration to show their photo galleries on the site.
Hello! For a reason I can’t comprehend, this page is the most visited page on my blog. If you’re looking for information about logging in Haxe, the “Logging and Tracing” page in the manual is a good start.
If you can be bothered, leave a comment and let me know what you’re looking for or how you came to be here. I’d love to know!
Jason.
Every week as part of my work and as part of my free time I get to work on Haxe code, and a lot of that is contributing to libraries, code, blog posts etc. Yesterday was one of those frustrating days where I told someone I’d finish a demo ufront app and show them how it works, but I just ran into problem after problem and didn’t get it done, and was feeling pretty crap about it.
After chatting it out I looked back at my week and realised: I have done alot. So I thought I should start keeping a log of what I’ve been working on – mostly for my own sake, so I can be encouraged by the progress I have made, even if I haven’t finished stuff yet. But also in case anything I’m working on sparks interest or discussion – it’s cool to have people know what I’m up to.
So I’d like to start a weekly log. It may be one of those things I do once and never again, or it may be something I make regular: but there’s no harm in doing it once.
So here we go, my first log. In this case, it’s not just this week, some of it requires me to go back further to include things I’ve been working on, so it’s a pretty massive list:
Node Webkit: On Monday’s I work at Vose Seminary, a tertiary college, and I help them get their online / distance education stuff going. Editing videos, setting up online Learning Management Systems etc. I have a bunch of command line utils that make the video editing / exporting / transcoding / uploading process easier, but I want to get these into graphics so other staff can use it. Originally I was thinking of using OpenFL / StablexUI. I’m far more comfortable with the JS / Browser API than the Flash API however, and so Node-Webkit looked appealing. On Monday I made my first Haxe-NodeJS project in over a year, using Clement’s new Node-API repo. It’s beautiful to work with, and within an hour and a half I had written some externs and had my first “hello-world” Node-Webkit app. I’ll be working on it again this coming Monday.
neko.Web.cacheModule: I discovered a way to get a significant speed-up in your web-apps. I wrote a blog post about it.
Ufront: I’ve done a lot of work on Ufront this week. After my talk at WWXthis year, I had some good chats with people and basically decided I was going to undertake a major refactor of ufront. I’m almost done! Things I’ve been working on this week (and the last several weeks, since it all ties in together):
Extending haxe.web.Dispatch (which itself required a pull request) to be subclassed, and allowing you to 1) execute the ‘dispatch’ and ‘executeAction’ steps separately and 2) allow returning a result, so that you can get the result of your dispatch methods. This works much nicer with Ufront’s event based processing, and allows for better unit testing / module integration etc. The next step is allowing dispatch to have asynchronous handlers (for Browser JS and Node JS). I began thinking through how to implement this also.
After discovering neko.Web.cacheModule, I realised that it had many implications for Ufront. Basically: You can use static properties for anything that is generic to the whole application, but you cannot use it for anything specific to a request. This led to several things breaking – but also the opportunity for a much better (and very optimised) design.
IHttpSessionState, FileSession: the first thing that was broken was the FileSession module. The neko version was implemented entirely using static methods, which led to some pretty broken behaviour once caching between requests was introduced. In the end I re-worked the interface “IHttpSessionState” to be fairly minimal, and was extended by the “IHttpSessionStateSync” and “IHttpSessionStateAsync” interfaces, so that we can begin to cater for Async platforms. I then wrote a fresh FileSession implementation that uses cookies and flat-files, and should work across both PHP and Neko (and in Future, Java/C#). The JS target would need a FileSessionAsync implementation.
IAuthHandler / EasyAuth: At the conference I talked about how I had an EasyAuth library that implemented a basic User – Group – Permission model. At the time, this also was implemented with Static methods. Now I have created a generic interface (IAuthHandler) so that if someone comes up with an auth system other than EasyAuth, it can be compatible. I also reworked EasyAuth to be able to work with different a) IHttpSessionState implementations and b) different IAuthAdapter’s – basically, this is an interface that just has a single method: `authenticate()`. And it tells you if the user is logged in or not. EasyAuth by default uses EasyAuthDBAuthAdapter, which compares a username and password against those in the database. You could also implement something that uses OpenID, or a social media logon, or LDAP, or anything. All this work trying to make it generic enough that different implementations can co-exist I think will definitely pay off, but for now it helps to have a well thought out API for EasyAuth :)
YesBoss: Sometimes you don’t want to worry about authentication. Ufront has the ability to create a “tasks.n” command line file, which runs tasks through a Command Line Interface, rather than over the web. When doing this, you kind of want to assume that if someone has access to run arbitrary shell commands, they’re allowed to do what they want with your app. So now that I have a generic interface for checking authentication, I created the “YesBossAuthHandler” – a simple class that can be used wherever an authentication system is needed, but any permission check it always lets you pass. You’re the boss, after all.
Dependency Injection: A while ago, I was having trouble understanding the need for Dependency Injection. Ufront has now helped me see the need for it. In the first app I started making with the “new” ufront, I wanted to write unit tests. I needed to be able to jump to a piece of code – say, a method on a controller – and test it as if it was in a real request, but using a fake request. Dependency injection was the answer, and so in that project I started using Minject. This week, realising I had to stop using statics and singletons in things like sessions and auth handling, I needed a way to get hold of the right objects, and dependency injection was the answer. I’ve now added it as standard in Ufront. There is an `appInjector`, which defines things that should be injected everywhere (modules, controllers, APIs etc). For example, injecting app configuration or a caching module or an analytics API. Then there is the dispatchInjector, which is used to inject things into controllers, and the remotingInjector, which is used to inject things into APIs during remoting calls. You can define things you want to make available at your app entry point (or your unit test entry point, or your standalone task runner entry point), and they will be available when you need them. (As a side note, I now also have some great tools for mocking requests and HttpContexts using Mockatoo).
Tracing: Ufront uses Trace Modules. By default it comes with two: TraceToBrowser and TraceToFile. Both are useful, but I hadn’t anticipated some problems with the way they were designed. In the ufront stack, modules exist at the HttpApplication level, not at the HttpRequest level. On PHP (or uncached neko), there is little difference. Once you introduce caching, or move to a platform like NodeJS – this becomes a dangerous assumption. Your traces could end up displaying on somebody else’s request. In light of this, I have implemented a way of keeping track of trace messages in the HttpContext. My idea was to then have the Controller and RemotingApiClass have a trace() method, which would use the HttpContext’s queue. Sadly, an instance `trace()` method currently does not override the global `haxe.Log.trace()`, so unless we can get that fixed (I’m chatting with Simon about it on IRC), it might be better to use a different name, like `uftrace()`. For now, I’ve also made a way for TraceToBrowser to try guess the current HttpContext, but if multiple requests are executing simultaneously this might break. I’m still not sure what the best solution is here.
Error Handling: I tried to improve the error handling in HttpApplication. It was quite confusing and sometimes resulted in recursive calls through the error stack. I also tried to improve the visual appearance of the error page.
Configuration / Defaults:The UfrontApplication constructor was getting absurd, with something like 6 optional parameters. I’ve moved instead to having a `UfrontConfiguration` typedef, with all of the parameters, and you can supply, all, some or none of the parameters, and fall-backs will be used if needed. This also improves the appearance of the code from:new UfrontApplication( true, “log.txt”, Dispatch.make(new Routes()) );
to
new UfrontApplication({ urlRewrite: true, dispatchConf: Dispatch.make( new Routes() ), logFile: “log.txt” });
More ideas: last night I had trouble getting to sleep. Too many ideas. I sent myself 6 emails (yes 6) all containing new ideas for Ufront. I’ll put them on the Ufront Trello Board soon to keep track of them. The ideas were about Templating (similar abstractions and interfaces I have here, as well as ways of optimising them using caching / macros), an analytics module, a request caching module and setting up EasyAuth to work not only for global permissions (CanAccessAdminArea), but also for item-specific permissions: do you have permission to edit this blog post?
NodeJS / ClientJS: after using NodeJS earlier in the week, I had some email conversations with both Clement and Eric about using Ufront on NodeJS. After this week it’s becoming a lot more obvious how this would work, and I’m getting close. The main remaining task is to support asynchronous calls in these 3 things: Dispatch action execution calls, HttpRemotingConnection calls, and database calls – bringing some of the DB Macros magic to async connections. But it’s looking possibly now, where as it looked very difficult only 3 months ago.
CompileTime: I added a simple CompileTime.interpolateFile() macro. It basically reads the contents of the file at macro time, and inserts it directly into the code, but it inserts it using String Interpolation, as if you had used single quotes. This means you can insert basic variables or function calls, and they will all go in. It’s like a super-quick and super-basic poor-man’s templating system. I’m already using it for Ufront’s default error page and default controller page.
Detox: this one wasn’t this week, but a couple of weeks ago. I am working on refactoring my Detox (DOM / Xml Manipulation) library to use Abstracts. It will make for a much more consistent API, better performance, and some cool things, like auto-casting strings to DOM elements:”div.content”.find().append( “<h1>My Content</h1>” );
My Work Project: Over the last two weeks I’ve updated SMS (my School Management System project, the main app I’ve been working on) to use the new Ufront. This is the reason I’ve been finding so much that needs to be updated, especially trying to get my app to work with “ufront.Web.cacheModule”.
Until now I haven’t had to worry much about the speed of sites made using Haxe / Ufront, – none of the sites or apps I’ve made have anywhere near the volume for it to be a problem, and the general performance was fast enough that no one asked questions. But I’m going to soon be a part of building the new Haxe website, which will have significant volume.
So I ran some benchmarks using ab (Apache’s benchmarking tool), and wasn’t initially happy with the results. They were okay, but not significantly faster than your average PHP framework. Maybe I would have to look at mod_tora or NodeJS for deployment.
Then I remembered something: a single line of code you can add that vastly increases the speed: neko.Web.cacheModule(main).
Benchmarks
Here is some super dumb sample code:
class Server {
static var staticInt = 0;
static function main() {
#if neko
neko.Web.cacheModule(main); // comment out to test the difference
#end
var localInt = 0;
trace ( ++staticInt );
trace ( ++localInt );
}
}
And I am testing with this command:
ab -n 1000 -c 20 http://localhost/
Here are my results (in requests/second on my laptop):
Apache/mod_php (no cache): 161.89
NekoTools server: 687.49
Apache/mod_neko (no cache): 1054.70
Apache/mod_tora (no cache): 745.94
Apache/mod_neko (cacheModule): 3516.04
Apache/mod_tora (cacheModule): 2185.30
First up: I assume mod_tora has advantages on sites that use more memory, but a dummy sample like this is more overhead than it’s worth.
Second, and related: I know these tests are almost worthless, we really need to be testing a real app, with file access and template processing and database calls.
Let’s do that, same command, same benchmark parameters:
Apache/mod_php (no cache): 3.6 (ouch!)
NekoTools server: 20.11
Apache/mod_neko (no cache): 48.74
Apache/mod_tora (no cache): 33.29
Apache/mod_neko (cacheModule): 351.42
Apache/mod_tora (cacheModule): 402.76
(Note: PHP has similar caching, using modules like PHP-APC. I’m not experienced setting these up however, and am happy with the neko performances I’m seeing so I won’t investigate further)
Conclusions:
the biggest speed up (in my case) seems to come from cacheModule(), not mod_tora. I believe once memory usage increases significantly, tora brings advantages in that arena, and so will be faster due to less garbage collection.
this could be made faster, my app currently has very little optimisation:
the template system uses Xml, which I assume isn’t very fast.
a database connection is required for every request
there is no caching (memcached, redis etc)
I think I have some terribly ineffecient database queries that I’m sure I could optimise
Ufront targeting Haxe/PHP is not very fast out-of-the-box. I’m sure you could optimise it, but it’s not there yet.
This is running on my laptop, not a fast server. Then again, my laptop may be faster than a low end server, not sure.
Usage
So, how does it work?
#if neko neko.Web.cacheModule( main ); #end
The conditional compilation (#if neko and #end) is just there so that you can still compile to other targets without getting errors. The cacheModule function has the following documentation:
Set the main entry point function used to handle requests.
Setting it back to null will disable code caching.
By entry point, it is usually going to mean the main() function that is called when your code first runs. So when the docs ask for a function to use as the entry point, I just use main, meaning, the static function main() that I am currently in.
I’m unsure of the impact of having multiple “.n” files or a different entry point.
The cache is reset whenever the file timestamp changes: so when you re-compile, or when you load a new “.n” file in place.
If you wanted to manually disable the cache for some reason, you use cacheModule(null). I’m not sure what the use case is for this though… why disable the cache?
Gotchas (Static variable traps with cacheModule)
The biggest gotcha is that static variables persist in your module. They are initialized just once, which is a big part of the speed increase. Let’s look at the example code I posted before:
class Server {
static var staticInt = 0;
static function main() {
#if neko
neko.Web.cacheModule(main); // comment out to test the difference
#end
var localInt = 0;
trace ( ++staticInt );
trace ( ++localInt );
}
}
With caching disabled, both trace statements will print “0” every time. With caching enabled, the staticInt variable does not get reset – it initializes at 0, and then every single page load will continue to increment it, it will go up and up and up.
What does this mean practically:
If you want to cache stuff, put it in a static variable. For example:
Database connections: store them in a static variable and the connection will persist.
Templates: read from disk once, store them in a static variable
App Config, especially if you’re passing JSON or Xml, put it in a static and it stays cached.
Things which should be unique to a request, don’t store in a static variable. For example:
Ufront has a class called NekoSession, which was entirely static methods and variables, and made assumptions that the statics would be reset between requests. Wrong! Having the session cached between different requests (by different users) was a disaster – everytime you click a link you would find yourself logged in as a different user. Needless to say we needed to refactor this and not use statics :) To approach it differently, you could use a static var sessions:StringMap<SessionID, SessionData> and actually have it work appropriately as long as the cache stayed alive.
Avoid singletons like Server.currentUser, or even User.current – these static variables are most likely going to be cached between requests leading to unusual results.
In case you’re interested, on my Personal Blog I have a post “Why the Pomodoro Technique Doesn’t Work For Me”. It’s about time management for creative workers. Have a look if you’re interested…
Paul Graham has written some great essays over time, and most of them hold up surprisingly well as they age. Take this article, “Five Questions About Language Design“. Written in May 2001. That’s over 12 years ago from today as I read it, and many of his predictions have come to pass (the dominance of web applications, the rise in popularity of niche programming languages), and most of his logic is still sound, and still insightful.
Two particular points I found interesting, and would be interesting to the Haxe community I spend most of my time in:
4. A Language Has to Be Good for Writing Throwaway Programs.
You know what a throwaway program is: something you write quickly for some limited task. I think if you looked around you’d find that a lot of big, serious programs started as throwaway programs. I would not be surprised if most programs started as throwaway programs. And so if you want to make a language that’s good for writing software in general, it has to be good for writing throwaway programs, because that is the larval stage of most software.
I think Haxe is beginning to show it’s strength here in gaming. People are using it for Ludlam Dare (write a game in a single weekend), and then later the game scales up to be a full-featured, multi-platform, often commercial game. Haxe is good for a quick win (especially when targetting flash), but then you have the options to target so many other platforms as your vision for your game/app expands.
I’d love to see ufront get this good. I have so many things I would like to use as an app, but which I don’t feel justify an ongoing subscription to an online company. Many of them could get an MVP (minimal viable product) out in a weekend, if the framework was good enough. And it’s getting good enough, but still a little way to go :)
And then this:
2. Speed Comes from Profilers.
Language designers, or at least language implementors, like to write compilers that generate fast code. But I don’t think this is what makes languages fast for users. Knuth pointed out long ago that speed only matters in a few critical bottlenecks. And anyone who’s tried it knows that you can’t guess where these bottlenecks are. Profilers are the answer.
Language designers are solving the wrong problem. Users don’t need benchmarks to run fast. What they need is a language that can show them what parts of their own programs need to be rewritten. That’s where speed comes from in practice. So maybe it would be a net win if language implementors took half the time they would have spent doing compiler optimizations and spent it writing a good profiler instead.
Nice insight. I sometimes worry that the code I’m writing will be slow. It’s hard to know if optimisations are worth it, especially if it may compromise code readability etc. A better solution would be to focus on making profiling easy. On the JS target you can easily use the browser tools to show profiling information. Another option is to bake it into your Haxe code, something that the “massivecover” lets you do. Wiring that support from massivecover into ufront or other frameworks, and generating pretty reports, would be a very cool way to encourage people to write fast apps.
If you ever come across this error, it can be a bit cryptic to understand.
Here’s some sample code that produces the error:
import haxe.macro.Expr;
import haxe.macro.Context;
import neko.Lib;
class BuildInMacroTests
{
public static function main() {
var s:MyModel = new MyModel();
MyMacro.doSomething( s );
}
}
class MyModel extends sys.db.Object // has a build macro
{
var id:Int;
var name:String;
}
private class MyMacro
{
public static macro function doSomething(output : Expr) : Expr {
return output;
}
}
I’m still not sure I have a full grasp on it, but here’s a few pointers:
It’s not necessarily an enum – it can happen with a class or interface that has a “@:build” macro also.
The basic sequence happens in this order:
BuildInMacrosTest.main() is the entry point, so the compiler starts there and starts processing.
When it hits “var s:MyModel”, it does a lookup of that type, realizes the class needs a build macro to run, and runs the build macro.
When it hits “MyMacro.doSomething()”, it types the expression, and realizes that it is a macro call. To run the macro, it must find the macro class, load it into the macro context, and execute it.
It finds the macro class, it’s in this file.
It tries to load this module (hx file) into the macro context, so it goes through the whole process of typing it again.
As it’s loading it into the macro context, it hits the “MyModel” build macro again, which it can’t do at macro time, so it spews out the error.
The basic solutions:
Wrap your build macro declarations in conditionals:
#if !macro @:build(MyMacro.build()) #end class Object { ... }
Wrap anything that is not a macro in conditionals:
#if !macro
class BuildInMacroTests {}
class MyModel {}
#else
class MyMacro {}
#end
Keep your macros in seperate files:
BuildInMacroTests.hx:
class BuildInMacroTests {
public static function main() {
var s:MyModel = new MyModel();
MyMacro.doSomething( s );
}
}
class MyModel extends sys.db.Object {
var id:Int;
var name:String;
}
MyMacro.hx:
import haxe.macro.Expr;
import haxe.macro.Context;
class MyMacro {
public static macro function doSomething(output : Expr) : Expr {
return output;
}
}
A combination of the 1st and 3rd solutions is probably usually the cleanest.
When targetting Haxe JS in Haxe 3, the output is “modern” style, which means, to prevent polluting the global namespace or conflicting with other libraries, the output is wrapped in a simple function:
(function() {})()
Which is great. And if you place breakpoints in your code, using:
js.Lib.debug();
Then your browser will launch the debugger inside this Haxe context, and you have access to all your classes etc. But what if you want to fire up the browser’s JS console, and gain arbitrary access to something in your Haxe code? Because it’s all hidden inside that function, you can’t.
Unless you have a workaround, which looks like this:
class Client
{
@:expose("haxedebug") @:keep
public static function enterDebug()
{
js.Lib.debug();
}
}
What’s going on: we have a class, and a function: “enterDebug”. This function can go in any class that you use, really – it doesn’t have to be in Client or your Main class or anything.
The “js.Lib.debug()” statement launches the debugger in the haxe context, as described before. But the “@:expose” metadata exposes this function outside of the Haxe context. The string defines what we expose it as: rather than the default “Client.enterDebug()”, we’ll just have “haxedebug()”. And the “@:keep” metadata makes sure this won’t get deleted by the compilers Dead Code Elimination, even though we may never explicitly call this function in our code.
Now that we’ve done that, recompile, and voilà! You can type “haxedebug()” into the Javascript console and start fiddling around inside the Haxe context. Enjoy.
I’ve looked at haxe.web.Dispatch before, and I thought it looked really simple – in both a good and a bad way. It was easy to set up and fast. But at first it looked like you couldn’t do complex URL schemes with it.
Well, I was wrong.
At the WWX conference I presented some of the work I’ve done on Ufront, a web application framework built on top of Haxe. And I mentioned that I wanted to write a new Routing system for Ufront. Now, Ufront until now has had a pretty powerful routing system, but it was incredibly obese – using dozens of classes, thousands of lines of code and a lot of runtime type checking, which is usually pretty slow.
Dispatch on the other hand uses macros for a lot of the type checking, so it’s much faster, and it also weighs in at less than 500 lines of code (including the macros!), so it’s much easier to comprehend and maintain. To wrap my head around the ufront framework took me most of the day, following the code down the rabbit hole, but I was able to understand the entire Dispatch class in probably less than an hour. So that is good!
But there is still the question, is it versatile enough to handle complex URL routing schemes? After spending more time with it, and with the documentation, I found that it is a lot more flexible than I originally thought, and should work for the vast majority of use cases.
Learning by example
Take a look at the documentation to get an idea of general usage. There’s some stuff in there that I won’t cover here, so it’s well worht a read. Once you’ve got that understood, I will show how your API / Routing class might be structured to get various URL schemes:
If we want a default homepage:
function doDefault() trace ( "Welcome!" );
If we want to do a single page /about/:
function doAbout() trace ( "About us" );
If you would like to have an alias route, so a different URL that does the same thing:
inline function doAboutus() doAbout();
If we want a page with an argument in the route /help/{topic}/:
function doHelp( topic:String ) {
trace ( 'Info about $topic' );
}
It’s worth noting here that if topic is not supplied, an empty string is used. So you can check for this:
function doHelp( topic:String ) {
if ( topic == "" ) {
trace ( 'Please select a help topic' );
}
else {
trace ( 'Info about $topic' );
}
}
Now, most projects get big enough that you might want more than one API project, and more than one level of routes. Let’s say we’re working on the haxelib website (a task I might take on soon), there are several pages to do with Projects (or haxelibs), so we might put them altogether in ProjectController, and we might want the routing to be available in /projects/{something}/.
As you can see, that gives a fairly easy way to organise both your code and your URLs: all the code goes in ProjectController and we access it from /projects/. Simple.
With that example however, all the variable capturing is at the end. Sometimes your URL routing scheme would make more sense if you were to capture a variable in the middle. Perhaps you would like:
Even this can still be done with Dispatch (I told you it was flexible):
function doUsers( d:Dispatch, username:String ) {
if ( username == "" ) {
println("List of users");
}
else {
d.dispatch( new UserController(username) );
}
}
And then in your username class:
class UserController {
var username:String;
public function new( username:String ) {
this.username = username;
}
function doDefault( project:String ) {
if ( project == "") {
println('$username\'s projects');
}
else {
println('$username\'s $project project');
}
}
function doContact() {
println('Contact $username');
}
}
So the username is captured in doUsers(), and then is passed on to the UserController, where it is available for all the possible controller actions. Nice!
As you can see, this better represents the heirarchy of your site – both your URL and your code are well structured.
Sometimes, it’s nice to give users a top-level directory. Github does this:
You can see here that Dispatch is clever enough to know what is a special route, like “about” or “projects/something”, and what is a username to be passed on to the UserController.
Finally, it might be the case that you want to keep your code in a separate controller, but you want to have it stay in the top level routing namespace.
To use a sub-controller add methods to your Routes class:
inline function doSignUp() (new AuthController()).doSignUp();
inline function doSignIn() (new AuthController()).doSignIn();
inline function doSignOut() (new AuthController()).doSignOut();
This will let the route be defined at the top level, so you can use /signup/ rather than /auth/signup/. But you can still keep your code clean and separate. Winning. The inline will also help minimise any performance penalty for doing things this way.
Comparison to Ufront/MVC style routing
Dispatch is great. It’s light weight so it’s really fast, and will be easier to extend or modify the code base, because it’s easier to understand. And it’s flexible enough to cover all the common use cases I could think of.
I’m sure if I twisted my logic far enough, I could come up with a situation that doesn’t fit, but for me this is a pretty good start.
There are three things the old Ufront routing could do that this can’t:
Filtering based on whether the request is Post / Get etc. It was possible to do some other filtering also, such as checking authentication. I think all of this can be better achieved with macros rather than the runtime solution in the existing ufront routing framework.
LocalizedRoutes, but I’m sure with some more macro love we could make even that work. Besides, I’m not sure that localized routes ever functioned properly in Ufront anyway ;)
Being able to capture “controller” and “action” as variables, so that you can set up an automatic /{controller}/{action}/{...} routing system. While this does make for a deceptively simple setup, it is in fact quite complex behind the scenes, and not very type-safe. I think the “Haxe way” is to make sure the compiler knows what’s going on, so any potential errors are captured at compile time, not left for a user to discover.
Future
I’ll definitely begin using this for my projects, and if I can convince Franco, I will make it the default for new Ufront projects. The old framework can be left in there in case people still want it, and so that we don’t break legacy code.
I’d like to implement a few macros to make things easier too.
So
var doUsers:UserController;
Would automatically become:
function doUsers( ?d:Dispatch, username:String ) {
d.dispatch( new UserController(username) );
}
The arguments for “doUsers()” would match the arguments in the constructor of “UserController”. If “username” was blank, it would still be passed to UserController.default, which could test for a blank username and take the appropriate action.
I’d also like:
@:forward(doSignup, doSignin, doSignout) var doAuth:AuthController;
To become:
function doAuth( ?d:Dispatch ) {
d.dispatch( new AuthController() );
}
inline function doSignup() (new AuthController()).doSignup();
inline function doSignin() (new AuthController()).doSignin();
inline function doSignout() (new AuthController()).doSignout();
Finally, it would be nice to have the ability to do different actions depending on the method. So something like:
@:method(GET) function doLogin() trace ("Please log in");
@:method(POST) function doLogin( args:{ user:String, pass:String } ) {
if ( attemptLogin(user,pass) ) {
trace ( 'Hello $user' );
}
else {
trace ( 'Wrong password' );
}
}
function doLogin() {
trace ( "Why are you using a weird HTTP method?" );
}
This would compile to code:
function get_doLogin() {
trace ("Please log in")
}
function post_doLogin( args:{ user:String, pass:String } ) {
if ( attemptLogin(user,pass) ) {
trace ( 'Hello $user' );
}
else {
trace ( 'Wrong password' );
}
}
function doLogin() {
trace ( "Why are you using a weird HTTP method?" )
}
Then, if you do a GET request, it first attempts “get_doLogin”. If that fails, it tries “doLogin”.
The aim then, would be to write code as simple as:
class Routes {
function doDefault() trace ("Welcome!");
var users:UserController;
var projects:ProjectController;
@:forward(doSignup, doSignin, doSignout) var doAuth:AuthController;
}
So that you have a very simple, readable structure that shows how the routing flows through your apps.
When I get these macros done I will include them in ufront for sure.
Example Code
I have a project which works with all of these examples, in case you have trouble seeing how it fits together.
In it, I don’t use real HTTP paths, I just loop through a bunch of test paths to check that everything is working properly. Which it is… Hooray for Haxe!